
Data teams face a fundamental infrastructure choice: use an official API, build custom web scrapers, buy a managed extraction service, or combine them. When evaluating api vs web scraping, the core distinction is structured curation versus raw flexibility.
An API provides official, structured access through authenticated endpoints with strict rate limits. Web scraping extracts live, observed data directly from browser-rendered HTML or frontend network responses.
Do not force a binary choice. The most resilient data pipelines treat web collection as a spectrum. The real value lies in building a framework that navigates official endpoints, hidden APIs, and proxy-backed scrapers based on your exact constraints around data completeness, infrastructure cost, and reliability.
[Key Takeaway]
Evaluate your data pipelines across a 5-path spectrum—ranging from official APIs to paid crawl models—to balance infrastructure costs against data quality.
API vs web scraping: the short answer
Use an API for stable, structured, and legally clear access when the vendor’s schema matches your exact needs. Scrape the web when APIs omit fields, lag behind live page updates, or restrict scale.
DirectAnswer:
API vs web scraping comes down to structure versus flexibility. An API provides official, structured data access through authenticated endpoints with strict rate limits. Web scraping extracts observed data directly from HTML or browser-rendered pages, offering flexibility when APIs are incomplete, unavailable, or restrict analytical scale.
What an API is
An API (Application Programming Interface) delivers structured data, typically via JSON or XML over REST or GraphQL protocols. It operates strictly within predefined authentication rules, quotas, and schemas. Developers rely on APIs because they require zero HTML parsing, guarantee a specific data contract, and integrate seamlessly into existing data pipelines.
What web scraping is
Web scraping extracts information from unstructured HTML, the Document Object Model (DOM), or by intercepting frontend network responses. You parse the exact data rendered to a human user. Teams scrape because live websites often display real-time, granular information that official APIs filter, delay, or intentionally omit.
API vs scraping comparison table
| Method | Reliability | Data completeness | Flexibility | Scalability | Maintenance | Legal clarity | Best fit |
|---|---|---|---|---|---|---|---|
| Official API | High (enforced by vendor) | Limited to defined schema | Low (vendor-controlled) | Capped by rate limits | Low | High | Transactional or core operational data |
| Web scraping | Variable (site-dependent) | High (matches live page) | High (you control logic) | Requires heavy infrastructure | High | Ambiguous (depends on ToS/nature of data) | Market intelligence or competitive research |
Note: This is the baseline. Real production systems use more than these two paths.
Why the "API vs scraping" binary breaks in production
APIs provide curated truth, while scraping provides observed truth. Real-world systems require evaluating source completeness, quiet API failures, and changing monetization models rather than defaulting to "APIs are always better."
Traditional engineering advice treats APIs as the golden standard and scraping as a messy hack. In modern production environments, that binary fails. You must evaluate your data access strategy based on completeness, freshness, reliability, and ownership risk.
APIs give you curated truth. Scraping gives you observed truth.
An API serves what the database owner permits. A scraper reads what the user actually sees.
Consider these three scenarios:
- E-commerce pricing: The API shows the base catalog price. The live page displays an active flash-sale discount.
- Inventory lag: Warehouse APIs update hourly. The product page immediately reflects a "sold out" status.
- Missing context: Job boards or review sites frequently withhold salary bands or negative reviews from their public API feeds to protect their monetization strategy.
APIs do not lie, but they are often filtered, delayed, or intentionally incomplete for analytical use cases.
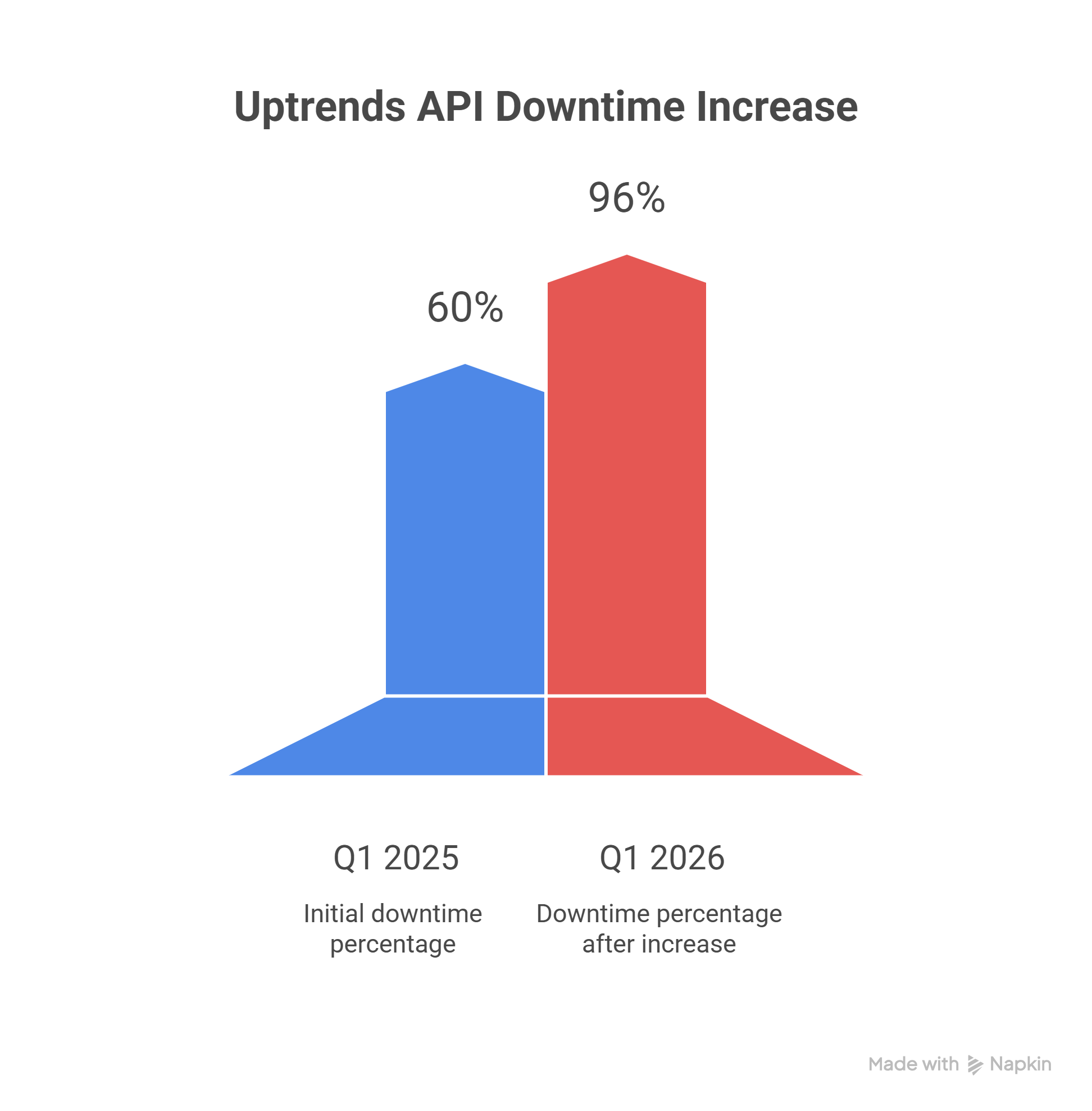
Reliability is not one-sided
Scrapers break visibly; a changed CSS selector immediately throws a parsing error. APIs, however, degrade silently through stale fields, sudden rate limiting, or partial payload responses. According to Uptrends, which analyzed 2 billion live API checks, average global API uptime fell from 99.66% to 99.46% between Q1 2024 and Q1 2025. Concurrently, average weekly downtime rose from 34 to 55 minutes. Assume APIs will fail quietly and build your failovers accordingly.
Access models change over time
The "API today, paywall tomorrow" problem is real. Vendors frequently deprecate useful fields or restrict usage abruptly. Simultaneously, scraping access models are evolving. Cloudflare’s recent launch of a Pay per Crawl marketplace proves that direct commercial agreements for AI bot access are becoming mainstream infrastructure.
[Action Item: Score your target source on completeness, freshness, and durability before choosing a data collection method.]
The 5-path data access spectrum
Web data extraction is a spectrum. Evaluate official APIs, hidden frontend APIs, managed scraping services, custom browser automation, and licensed data to find your optimal path.
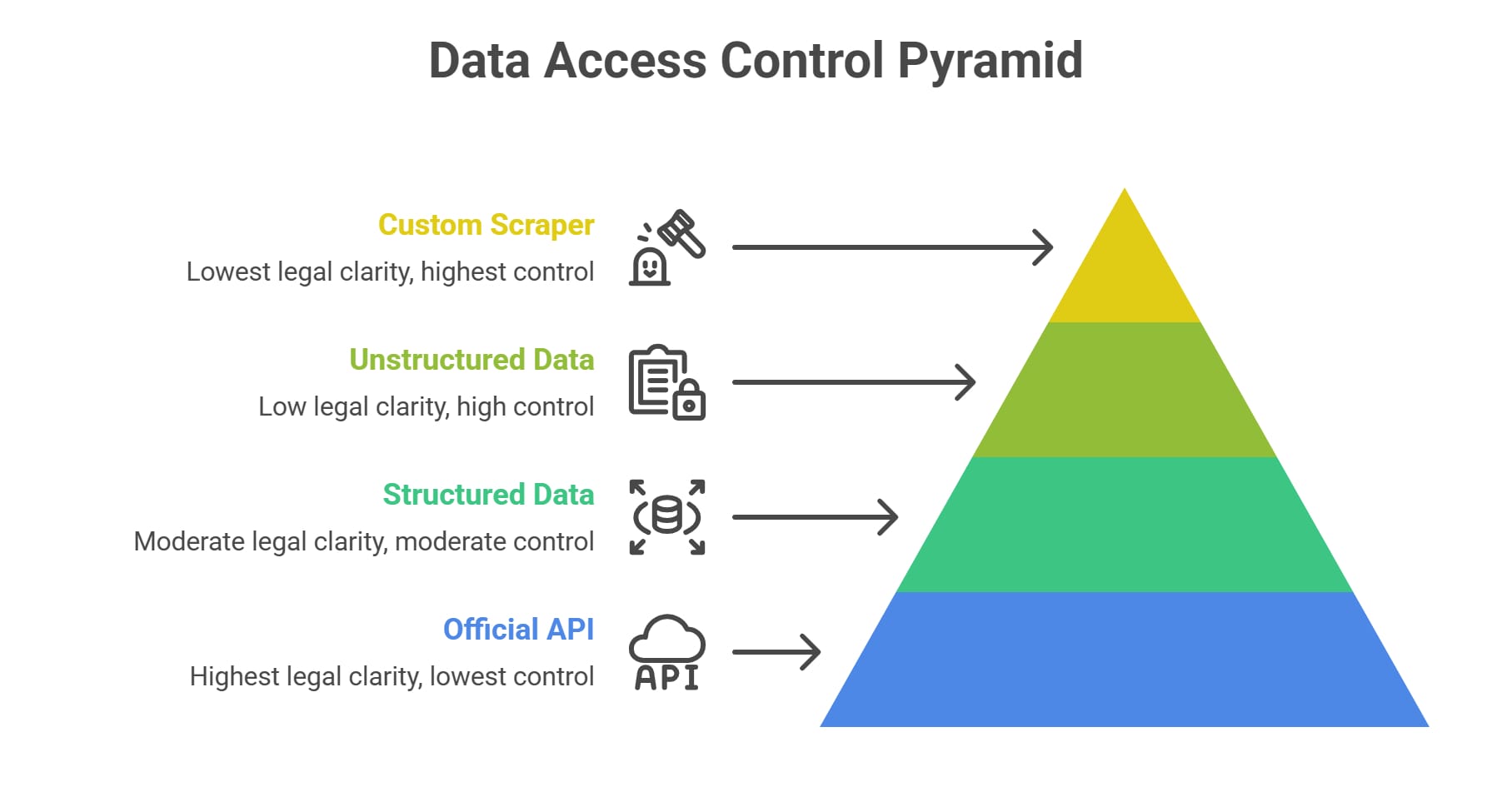
Do not limit your architecture to two options. Treat data collection as a 5-path spectrum of trade-offs. The global web scraping market was valued at USD 1.03B in 2025 and is projected to reach USD 2.23B by 2031—scraping is enterprise infrastructure, not a temporary workaround.
1. Official/public API
Best for authenticated or transactional workflows and compliance-sensitive deployments. Constraints include strict rate limits, incomplete data fields, pricing volatility, and deep vendor dependency.
2. Hidden or undocumented frontend API
The highly effective, missing middle ground. Websites rely on internal JSON or GraphQL endpoints to populate their own frontends.
How to check for a hidden API:
- Open your browser DevTools.
- Navigate to the Network tab.
- Filter by XHR/fetch requests.
- Reload the page and look for JSON endpoints and query parameters.
Intercepting a hidden API cuts DOM parsing maintenance to zero while delivering structured data.
3. Managed scraping API / scraping service
Buying the difficult infrastructure layer. You outsource proxy rotation, CAPTCHA solving, and headless browser management. You trade granular control for dramatically faster launch times and reduced engineering overhead.
4. Custom scraper / browser automation stack
Owning extraction end-to-end using Playwright or Puppeteer. The upside is absolute control and a strategic data moat. The heavy cost is perpetual maintenance, constant anti-bot engineering, and on-call responsibility.
5. Paid crawl or marketplace access
Some sites no longer fit the classic assumptions. Licensing and paid crawl models are the right answer when legal clarity matters more than raw control. Platforms now actively bridge the gap by charging bots directly for high-quality extraction access.
[Action Item: If a hidden API already exposes the fields you need in the Network tab, stop there before building a browser-based scraper.]
When to use an API vs scraping
Match the access method to your operational requirements. Use APIs for compliant, structured data; use scraping when page-level truth and broader field coverage outweigh the maintenance burden.
Choosing when to use an API vs scraping requires isolating your exact pipeline constraints.
Use an official API when…
- The API exposes the full schema your business logic actually requires.
- Vendor quotas comfortably fit your planned query volume.
- The API’s freshness SLA is acceptable for your use case.
- You require explicit permissions or authenticated data.
Use a hidden API when…
- The target page already calls structured JSON directly.
- Data is fully visible in the network tab without needing heavy browser rendering.
- DOM-level scraping would introduce unnecessary fragility.
Use scraping when…
- No API exists for the target domain.
- The official API intentionally omits high-value fields (pricing, reviews, historical context).
- Page-level truth matters more than database-level truth.
- You require broad coverage across hundreds of sites with non-existent or inconsistent APIs.
Run the API fitness test before you choose
Do not assume an official API handles analytical scale. Check:
- Field coverage mapping.
- Historical rate limits.
- Freshness SLAs.
- Deprecation risk.
Official APIs frequently fail at scale. Developers targeting Reddit for analytics quickly hit a practical 1,000-post pagination ceiling for subreddit listings, discovering that pulling high-volume comments via the official route slows pipelines to a crawl under strict rate limits.
Scraping API vs custom scraper: buy or build?
Buy when infrastructure is context; build when data collection is your core moat. Understand your scale, operational capacity, and lock-in risks before building an in-house scraping stack.
When evaluating a scraping API vs custom scraper, apply one absolute rule: Buy when infrastructure is context. Build when data collection is core.
Apply the core vs context rule
Core: Data extraction uniqueness is your primary moat, your standalone product, or your main margin driver. Build custom.
Context: Scraping is merely a necessary input feeding a downstream workflow or LLM agent. Buy managed infrastructure.
Buy when infrastructure is context
Buying managed infrastructure fits best when:
- Speed to launch dictates product success.
- You must manage hundreds of moving target domains.
- Your product’s true value is the downstream insight, not the crawl itself.
Build when data is core
Building custom infrastructure makes sense when:
- Target domains are strategically vital and highly specialized.
- You require custom interaction logic beyond what generic APIs provide.
- You possess deep engineering capacity to own reliability and anti-bot mitigation long-term.
Target difficulty dictates success. Proxyway’s industry benchmark report highlights that “buying” generic API requests is not a magic bullet: the hardest targets averaged just 21.88% success on Shein, 36.63% on G2, and 43.75% on Hyatt at 2 requests per second.
For AI startups and automation-heavy workflows, buying the infrastructure layer via managed platforms like Olostep allows teams to issue batch collection requests and receive normalized JSON. This bypasses the operational friction of maintaining proxies, unblocking logic, and DOM parsers entirely.
Hidden costs of building scraping infrastructure
List-price comparisons are fundamentally flawed. Calculate the failure-adjusted Total Cost of Ownership (TCO) by factoring in proxy pools, browser rendering costs, and engineering maintenance to find your true cost per usable record.
Evaluating when to buy vs build scraping infrastructure requires looking beneath vendor pricing pages. You must calculate the cost per usable record.
The real engineering burden
You are not just writing a Python script. You must build, host, and monitor distributed worker queues, robust retry systems, scalable storage, and strict job isolation logic.
Proxies and anti-bot systems
Your system requires residential proxy pools to bypass datacenter blocking. You must actively manage CAPTCHA solving, TLS fingerprinting, dynamic headless browser signatures, and Web Application Firewalls (WAFs) hunting your bots.
Parser drift and QA
Websites change constantly. Selectors break, layouts shift, and fields disappear. Maintenance involves writing data validation checks, maintaining test fixtures, configuring alerts, and engaging engineers on-call to preserve data integrity.
Failure-adjusted TCO formula
Model reality using this explicit formula:
Advertised Request Cost × Retries × Failure Rate + Engineering/QA Overhead = Real Cost per Usable Record
Cheap generic requests become wildly expensive if they fail 70% of the time. Pangolin modeled a 3-year TCO comparison highlighting roughly $925K for a fully scaled in-house build versus $155.4K when utilizing managed APIs alongside one data engineer.
Hybrid scraping architecture: how it works
Do not rely on a single failure point. Build hybrid pipelines that use APIs for primary data ingestion, scraping for missing fields, and strict normalization layers to keep downstream systems stable.
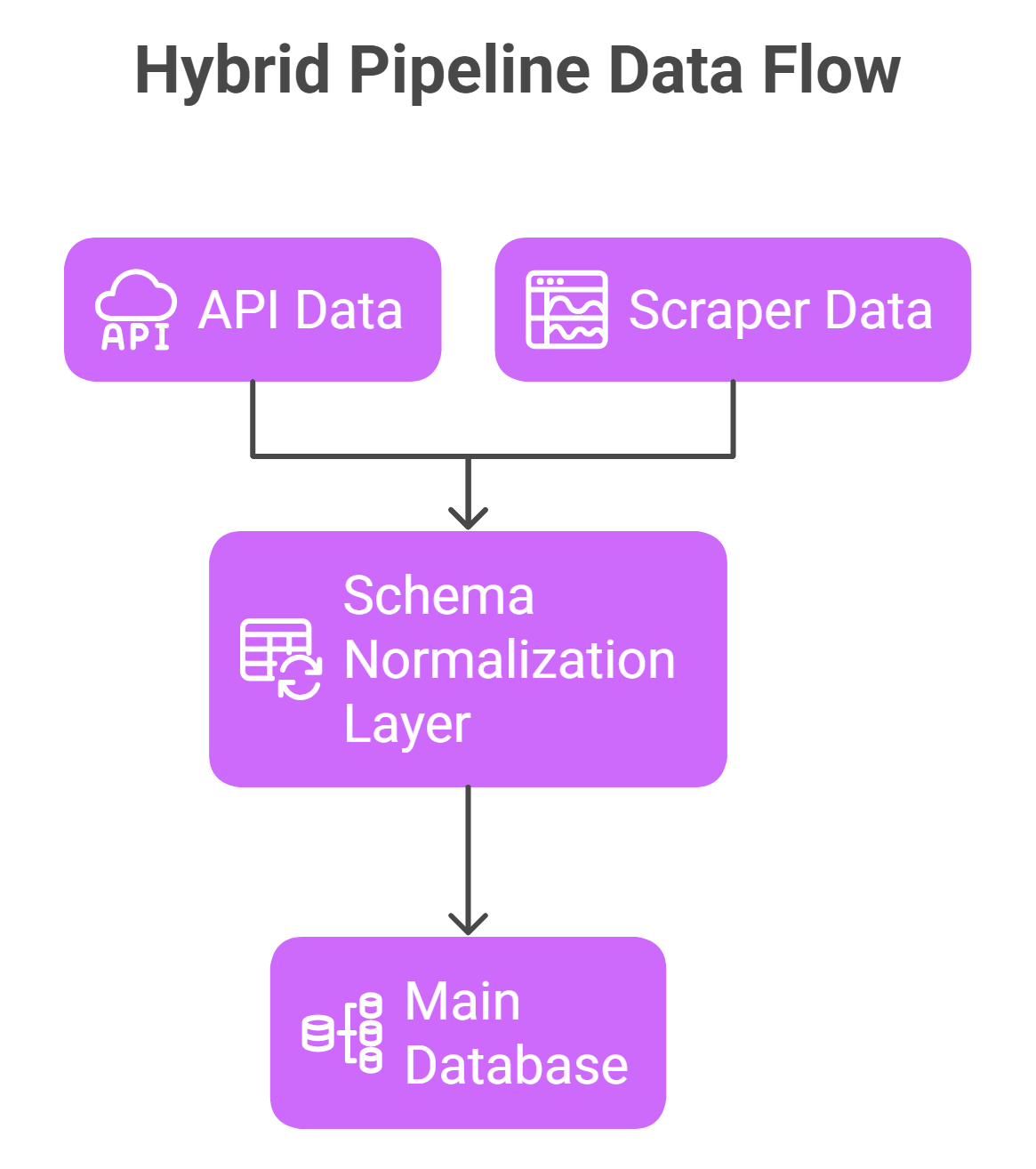
A hybrid scraping architecture combines official APIs and extracted data to eliminate single points of failure.
Pattern 1: API first, scraper fallback
The official API acts as the primary ingestion source. The scraper stays dormant, firing only to fill gaps during API outages, rate-limit pauses, or known stale data windows. Ideal for operational failovers.
Pattern 2: API for metadata, scraping for missing fields
The API provides structured entity IDs or pagination limits. The scraper iterates through those IDs to enrich the database with page-only fields hidden from the API. Ideal for e-commerce listings and real estate extraction.
Pattern 3: Managed scraping for hard targets, custom stack for moat data
You outsource proxy and CAPTCHA handling for heavily protected targets to a vendor. You retain your custom extraction logic in-house only for niche sites constituting your core strategic moat.
Design rules for a stable hybrid pipeline
- Source priority and failover logic: Define mathematically which source wins conflicts. Example: “Use API if freshness is < 15 minutes; otherwise, override with extracted page data.”
- Freshness SLAs: Operate in freshness windows. Source-specific SLAs dictate when to trigger expensive scraper overrides.
- Schema normalization: Downstream AI agents should never know whether a record originated from an API or a DOM parser. Design a strict canonical schema that standardizes outputs early.
- Portability layer: Reduce lock-in by building an abstraction layer. Managed extraction layers like Olostep fit naturally here as a single abstracted component within a broader hybrid stack, normalizing unstructured pages into clean JSON without dictating the rest of your architecture.
Practical architectures by use case
Tailor your architecture to the business goal. Market intelligence needs broad coverage, AI agents need structured runtime execution, and research tools need batch-processing stability.
Startup market intelligence platform
- Goal: Monitor competitor pricing and inventory across hundreds of domains.
- Best source mix: Official APIs where partnered, hidden APIs for structured list discovery, managed extraction for guarded e-commerce details.
- Main failure mode: Scaling custom DOM parsers internally before proving product-market fit.
AI agents gathering web data
- Goal: Dynamically search, retrieve, and synthesize information on demand.
- Best source mix: Discovery + retrieval pipelines prioritizing clean JSON output over raw HTML.
- Main failure mode: Allowing the agent to blindly execute heavy browser automation on simple text-based sites.
Research tools monitoring large datasets
- Goal: Maintain deep, historical datasets with verifiable accuracy.
- Best source mix: Recurring batch jobs mixing API backfills and broad completeness scraping.
- Main failure mode: Ignoring storage bloat and QA requirements as the target list scales.
Legal and policy constraints to factor in
Official APIs generally offer the safest legal path. Public data scraping still carries risk regarding Terms of Service, copyright, and platform security circumvention. Informational only, not legal advice.
Why official APIs are the safest path
APIs operate within a defined permission model. They carry significantly lower dispute risks and offer clear auditability of what data was pulled, when, and under what contractual agreement.
Why public data is not the whole legal answer
Assuming "publicly visible means legally safe to scrape" is a dangerous oversimplification. Legal risk extends beyond public access into Terms of Service (ToS) violations, copyright infringement, personal privacy regulations, and technical circumvention issues.
Platform enforcement is escalating
In December 2025, Google sued SerpAPI under the Digital Millennium Copyright Act (DMCA) for circumventing its SearchGuard protection measures to scrape search results at scale. This illustrates an aggressive shift toward platform enforcement against scraping intermediaries, proving that technical circumvention carries genuine risk regardless of the data's public visibility.
Practical risk-reduction checklist:
- Review ToS and explicit vendor permissions thoroughly.
- Never cross authenticated boundaries (login screens) with a scraper unless explicitly authorized.
- Minimize the collection of Personally Identifiable Information (PII).
- Document robust data provenance (source, timestamp, method).
Decision framework: choose your path in 8 questions
Use this 8-question diagnostic to bypass the "build vs buy" debate. Match your data requirements to the lowest-maintenance source capable of meeting your quality bar.
- Does an official API exist for the target?
- Does that API expose the exact fields your business logic requires?
- Does the API meet your concurrency volume and freshness SLA?
- Is the API pricing stable and viable for your profit margins?
- Is the target data exposed freely through frontend network calls (hidden API)?
- Is the target site aggressively protected or expensive to unblock?
- Is this specific data extraction core to your product moat, or just context?
- Do you need a secondary fallback or audit layer?
Final rule of thumb
Start with the lowest-maintenance source that meets your quality bar. Add scraping only when the API definitively falls short. Build custom infrastructure only when total ownership creates genuine, measurable strategic value.
FAQ
If an official API exists, should I always use it?
Not automatically. Use the official API if it meets your freshness, completeness, and rate-limit needs. If the API omits critical data fields (like reviews or exact pricing), limits analytical scale, or prices you out, fall back to a hidden API or hybrid scraping strategy.
What’s the difference between an official API and a scraping API?
An official API is maintained by the data owner to provide structured, authorized access. A scraping API is managed by a third-party vendor; it executes browser automation, proxy rotation, and anti-bot circumvention to extract unstructured data from target websites and return it to you as clean JSON.
What is a hidden or undocumented API?
A hidden API is the backend JSON or GraphQL endpoint a website uses to populate its own frontend. Inspecting your browser's network traffic often reveals these endpoints, allowing you to pull structured data directly without maintaining fragile DOM scrapers.
When should I build my own scraper instead of buying a service?
Build your own scraper when extraction logic is the core proprietary moat of your business, targets require complex interaction logic, and you have the engineering depth to handle constant anti-bot updates. Buy a service when scraping is just contextual data feeding a downstream workflow.
How do I estimate the true cost of scraping infrastructure?
Do not rely on vendor request pricing. Calculate your cost per usable record: multiply the advertised request cost by your retry rate and target failure rate, then add the engineering overhead required for proxy management, parser QA, and on-call maintenance.
When does a hybrid API + scraping architecture make sense?
Hybrid architecture is required when an official API lacks completeness or reliability. Use the API for fast, structured metadata ingestion and deploy scrapers selectively to fill in missing page-level fields, audit API accuracy, or trigger fallbacks during API outages.
The most effective strategy rarely forces a rigid choice between APIs and scraping in isolation. Winning architectures deploy the access method perfectly matching your immediate data quality needs, team engineering capacity, and long-term compliance risk.
To bypass the operational friction of owning heavy infrastructure, map your exact data requirements and fallback logic before evaluating managed extraction. Take one priority target through the 8-question framework today to clarify exactly where your pipeline needs to pull api vs web scraping data.