
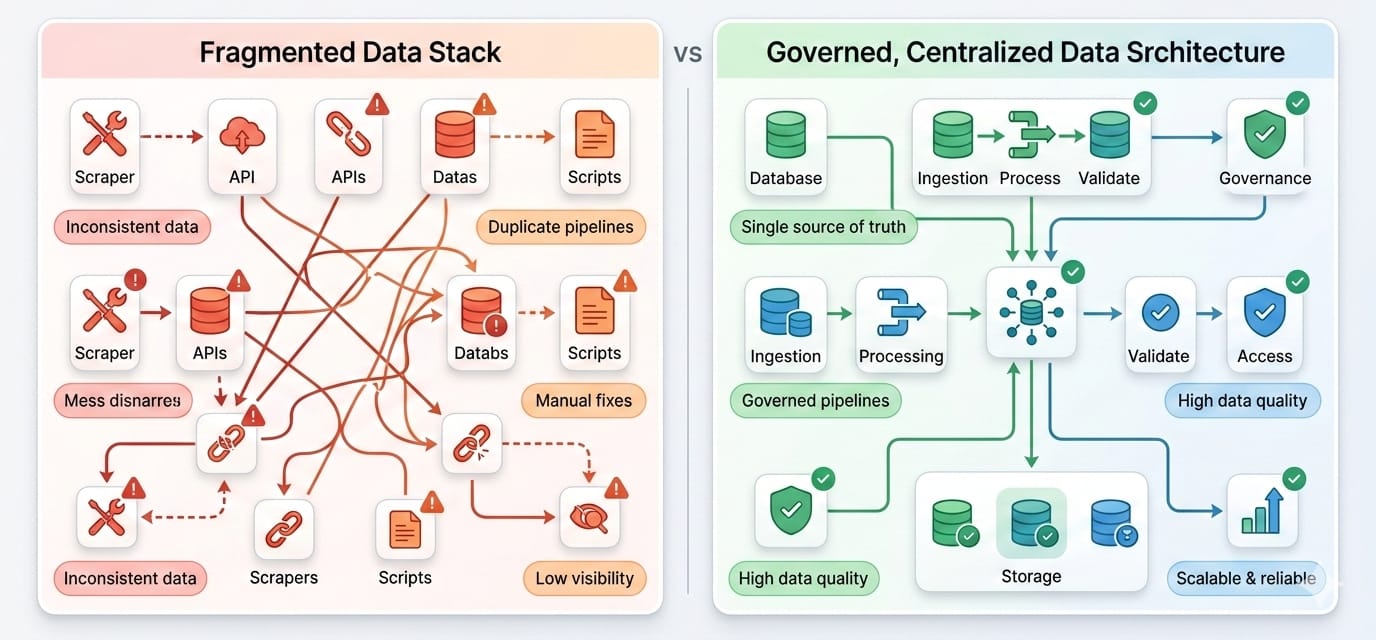
Most enterprises are drowning in applications but starving for integrated data. The average organization deploys roughly 900 applications, yet fully integrates less than 30% of them.
This connectivity gap actively destroys AI and analytics ROI. Teams with strong integrations report a 10.3x ROI on AI initiatives, compared to just 3.7x for those with fragmented stacks.
What is data sourcing?
Data sourcing is the end-to-end operational process of identifying, selecting, acquiring, ingesting, and validating data from internal and external origins. It transforms raw, scattered information into a reliable, governed supply chain for business intelligence, operational automation, and AI workflows.
The core issue you face is not a lack of data access. It is a lack of trust. When 77% of organizations rate their data quality as average or worse, building a modern data sourcing strategy becomes the only way to dictate how you choose sources, feed pipelines, and prevent source sprawl.
- The Definition: The governed supply chain of selecting, acquiring, and maintaining data.
- The Strategy: High-trust data sourcing starts with fewer, verified sources rather than an unfiltered accumulation of raw inputs.
- The Application: Map your sourcing problem, choose the precise collection method, and route clean data to analytics and AI models.
Want the practical version fast? Jump to the SOURCE framework or the data collection methods comparison below.
Understanding Data Sourcing
Instead of just grabbing datasets, a strong sourcing strategy dictates how you evaluate endpoints, enforce schemas, and maintain pipeline health over time.
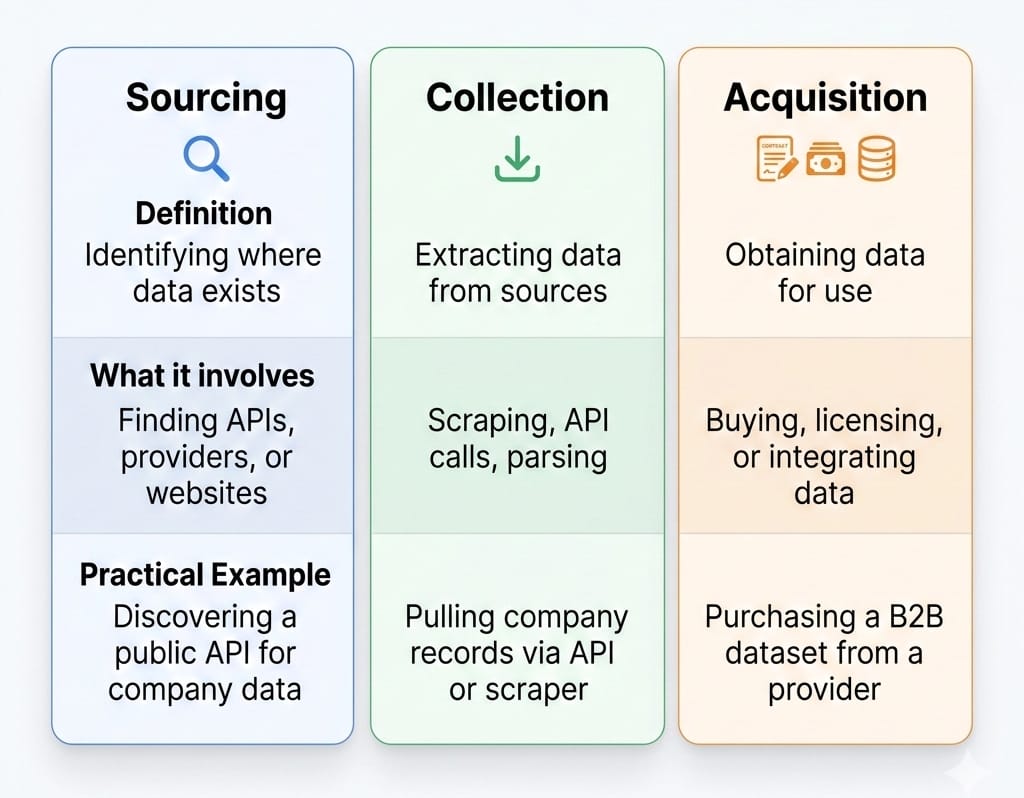
Data collection vs. data acquisition vs. data sourcing
These terms are frequently conflated, but they represent different stages of maturity:
- Data collection is the raw technical act of gathering information (example: scraping a website or logging application events).
- Data acquisition is obtaining legal or technical access to a specific dataset, often through purchasing from an outside vendor.
- Data sourcing is the overarching operating model. It encompasses collection and acquisition, but adds governance, pipeline routing, and lifecycle maintenance.
Why data sourcing matters
Strong sourcing protocols directly drive business outcomes. Verified inputs create trustworthy executive dashboards. Clean pipelines yield accurate machine learning predictions. Grounded contexts allow AI agents to act without hallucinating. Controlled ingestion lowers compliance risk under strict frameworks like the EU AI Act and reduces the sheer volume of broken pipelines your engineering team must fix.
Quick examples of data sourcing
- Data Engineering Teams: Pulling CRM updates, product telemetry, and financial logs into a central cloud warehouse via Change Data Capture (CDC).
- Growth Teams: Enriching inbound account lists with firmographic details from a third-party API provider.
- AI Platform Teams: Sourcing internal documentation and real-time public web context to power a Retrieval-Augmented Generation (RAG) agent.
If you skip classifying your data correctly first, your pipeline will inevitably break.
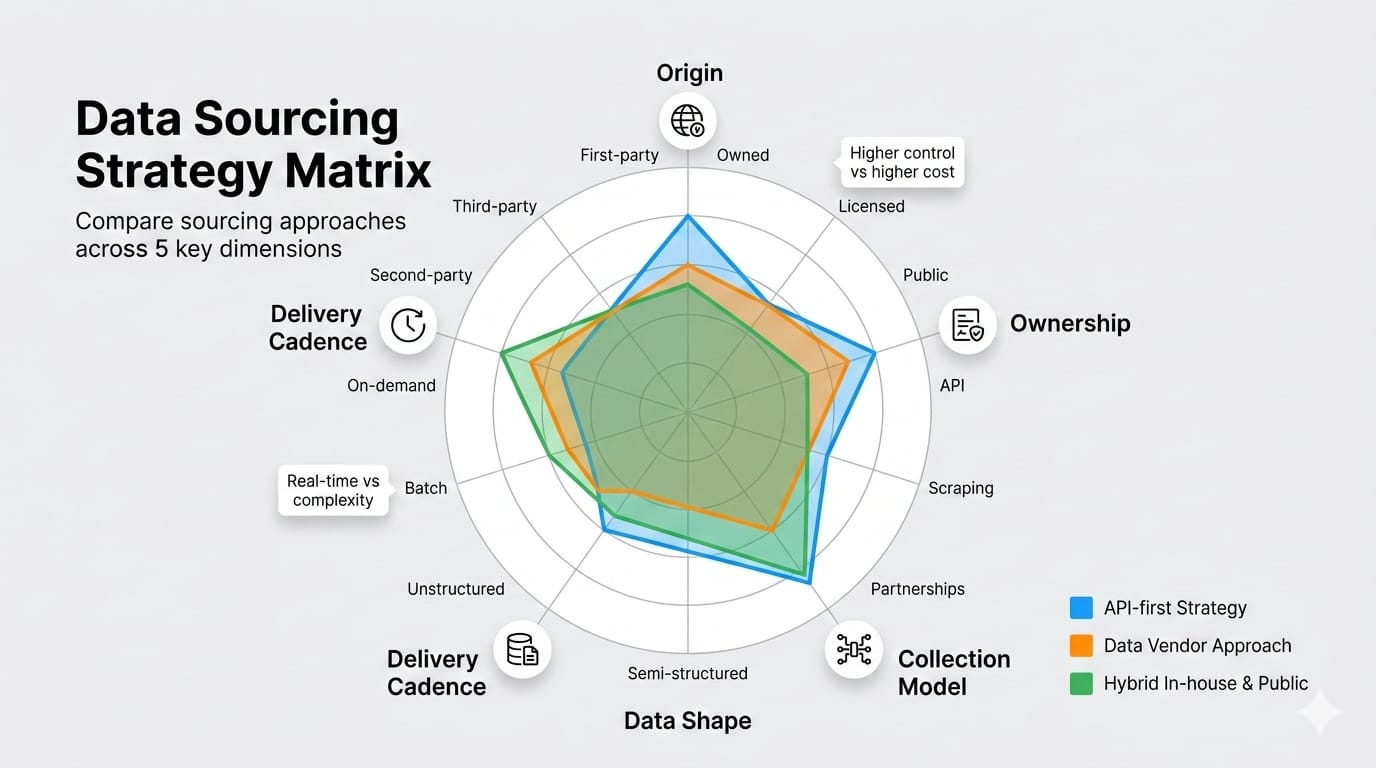
Data Sourcing Methods: A 5-Axis Classification Map
Categorizing your sourcing problem prevents architectural mistakes. Treat this 5-axis map as a decision matrix to define your exact needs before you write a single line of code or evaluate data sourcing tools.
1. Internal vs. external data
- Internal data: Proprietary information generated within your own systems (product telemetry, ERP ledgers, support tickets). This is your highest-trust baseline.
- External data: Information sourced from outside the organization (public web content, competitor pricing, market indicators). Use this strictly for enrichment or competitive intelligence.
2. First-party vs. second-party vs. third-party data
- First-party: Data you collect directly from your users.
- Second-party: Another organization's first-party data shared directly with you via a strategic partnership.
- Third-party: Data aggregated, packaged, and resold by outside vendors.
3. Manual vs. automated sourcing
- Manual: Valid for one-off research, initial source validation, or highly contextual low-volume extraction.
- Automated: Mandatory when the workflow is recurring, highly time-sensitive, or feeds multiple downstream consumers.
4. Structured vs. semi-structured vs. unstructured data
- Structured data: Highly organized formats like relational database tables.
- Semi-structured data: Loosely organized payloads with hierarchical tags (JSON, XML).
- Unstructured data: Raw formats like PDFs, public webpages, and text documents. Unstructured inputs now dominate modern AI and search workflows.
5. Delivery cadence (Batch vs. Streaming)
Tie your pipeline speed directly to your decision speed. Frame latency as a freshness choice to manage cloud compute costs, not as an engineering maturity badge.
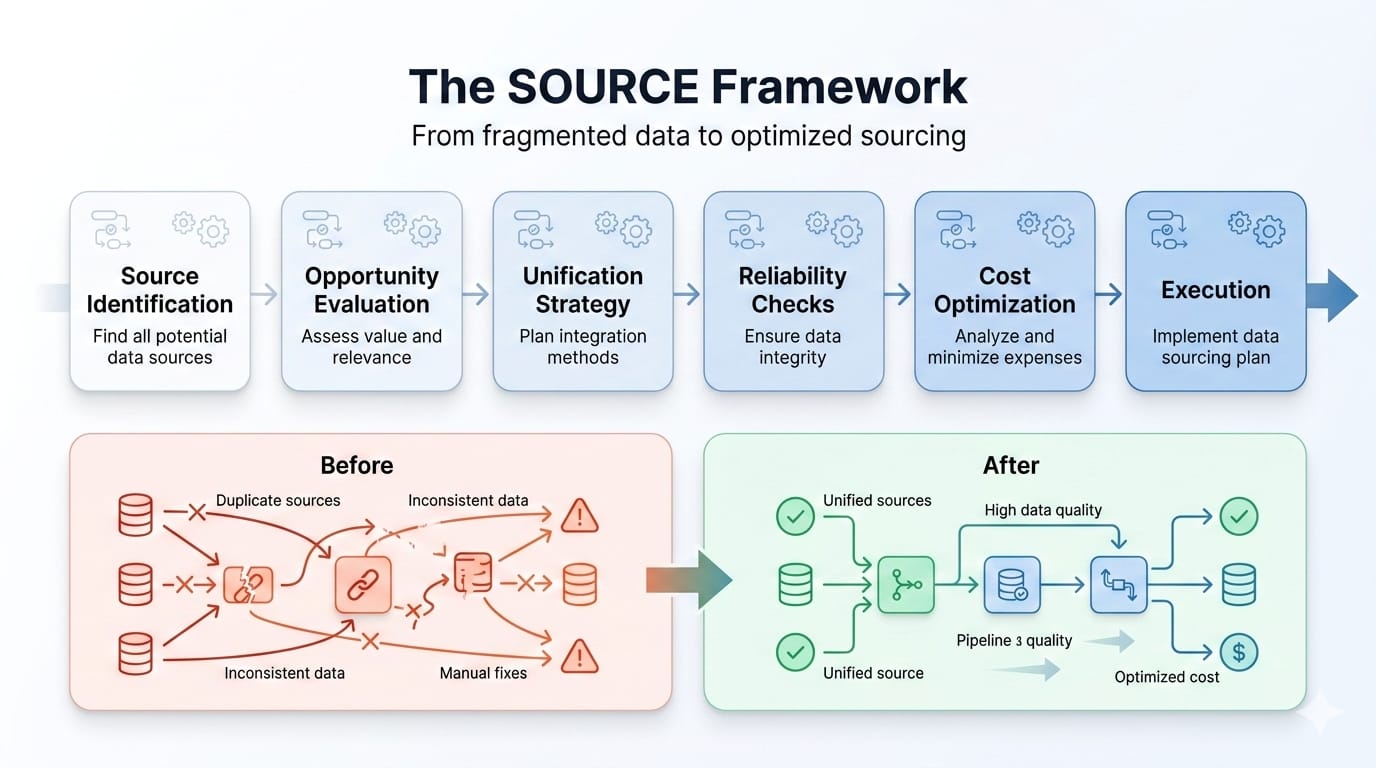
How to Build a Data Sourcing Strategy: The SOURCE Framework
The SOURCE framework functions as a reusable operating model. It shifts your team away from hoarding datasets and toward building a governed supply chain.
S = Scope the business need
Identify the exact requirement before connecting a new API.
- What we recommend: Ask what decision or workflow the data supports. Define the consumers, the required granularity, and the business impact if the data is wrong.
- Output: A scoped requirements document.
O = Optimize the source mix
Prevent overlapping datasets.
- What we recommend: Start with internal sources. Identify specific external gaps. Determine whether first-party collection or a third-party purchase delivers the best ROI.
- Output: An approved list of primary and secondary sources.
U = Use the right collection method
Match the extraction protocol to the source type.
- What we recommend: Evaluate APIs, file deliveries, webhooks, or web crawling. Base your decision on expected volume, endpoint reliability, and target data shape.
- Output: An architectural ingestion plan.
R = Route data into pipelines
Determine how the payload reaches its final destination.
- What we recommend: Map where data ingestion, data transformation, and data enrichment fit. Decide if the destination is a data warehouse, a vector store, or a downstream application.
- Output: A mapped data flow architecture.
C = Control trust
Enforce data quality and legal rights.
- What we recommend: Implement strict schema validation checks. Verify your legal rights to use the payload, supporting automated deletion workflows to comply with regulations.
- Output: A governance and compliance checklist.
E = Evolve continuously
Maintain pipeline health over time.
- What we recommend: Define refresh cadences. Monitor endpoint uptime and schema drift. Schedule quarterly rationalization reviews to retire obsolete sources.
- Output: An automated pipeline monitoring system.
Better data sourcing usually starts with fewer sources. Use the SOURCE framework to audit your current stack and kill redundant vendor feeds.
If public web data is one of your external gaps, review the Olostep documentation overview to see how search, scrape, crawl, and parse workflows consolidate into a single API.
9 Data Collection Methods: When to Use Each One
Different data acquisition challenges require specific technical approaches. Here is how to evaluate the primary data collection methods.
1. Direct database replication and CDC
- Best for: Internal operational systems requiring low-latency analytics.
- Strengths: Highly reliable and extremely fast. Change Data Capture (CDC) only moves new records, saving compute.
- Limits: Introduces tight schema coupling between operational databases and analytical teams.
2. APIs
- Best for: Stable, permissioned access to external SaaS platforms.
- Strengths: Highly reliable when API contracts and rate limits are well documented.
- Limits: Requires constant engineering maintenance when vendors update or deprecate endpoints.
3. File delivery (Cloud buckets and SFTP)
- Best for: Scheduled data handoffs and legacy partner integrations.
- Strengths: Simple to set up. Standard in enterprise environments.
- Limits: Weak freshness. Highly vulnerable to formatting and encoding errors.
4. Webhooks and event streams
- Best for: Event-driven system updates.
- Strengths: Ideal when downstream operational actions depend on instant record delivery.
- Limits: High architectural complexity. Difficult to debug when events fail to trigger.
5. Manual exports and surveys
- Best for: Low-volume, high-context exploratory workflows.
- Strengths: Zero engineering overhead.
- Limits: Completely unsuited for recurring production pipelines.
6. Public and open datasets
- Best for: Benchmarking, geospatial mapping, and regulatory tracking.
- Strengths: Free and highly authoritative.
- Limits: Usually requires heavy internal validation and custom refresh planning.
7. Third-party data providers
- Best for: Rapid market coverage expansion and sales lead enrichment.
- Strengths: Exceptional speed to market.
- Limits: High risk of poor data quality. You must trial the match rate and test freshness before buying.
8. Web data collection and licensed crawling
- Best for: Competitive intelligence, public web research, and AI context grounding.
- Strengths: Grants access to the largest dataset on earth.
- Limits: Operationally messy without specialized infrastructure. Rights management, anti-bot bypasses, and page volatility require constant maintenance.
Infrastructure Note: If you need public web data in structured formats without running a headless browser fleet, Olostep provides dedicated endpoints. The /scrapes endpoint returns clean markdown or JSON. Teams use /crawls for subpage discovery and /parsers to convert unstructured pages into backend-friendly payloads. (Explore the documentation).
9. Unstructured document ingestion
- Best for: Manuals, product sheets, customer support logs, and RAG corpora.
- Strengths: Unlocks deep proprietary knowledge.
- Limits: Requires advanced optical character recognition, chunking, and embedding to become searchable.

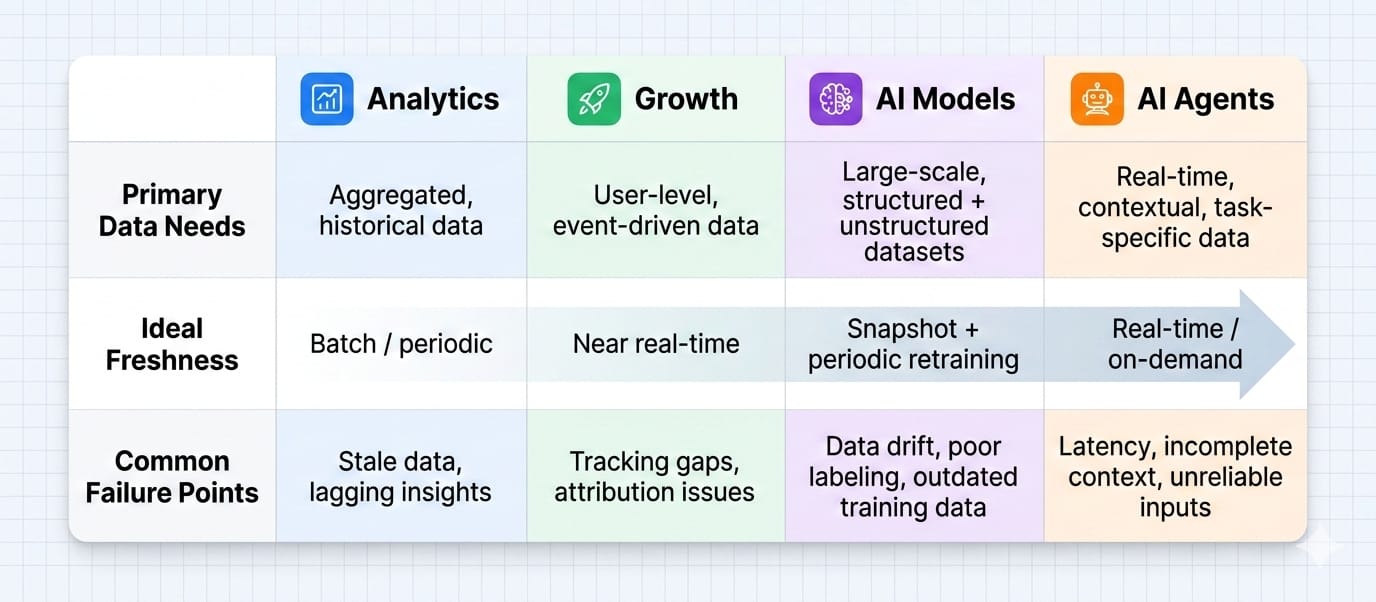
Sourcing Data for Analysis vs. AI vs. Growth
Different consumers require vastly different data architectures and latency tolerances.
Data sourcing for analytics and business intelligence
- Inputs: Product events, CRM updates, financial ledgers.
- Cadence: Daily or hourly batch delivery.
- Failure points: Inconsistent metric definitions across departmental silos destroy dashboard trust.
Data sourcing for growth and lead enrichment
- Inputs: First-party CRM records acting as the base, enriched by external website intelligence and intent signals.
- Cadence: High reliance on rapid micro-batch refresh jobs.
- Failure points: Ignoring data decay. Accepting low match rates from third-party vendors.
Data sourcing for AI models
- Inputs: Massive combinations of structured logs and unstructured documents.
- Cadence: Periodic historical batching.
- Failure points: Ignoring data provenance, representativeness, and legal usage rights.
- Insight: "More data is always better" is a flawed assumption. Highly curated, high-quality subsets often yield better model performance than unfiltered data dumps.
Data sourcing for AI Agents and RAG
- Inputs: Permission-aware internal documentation and real-time public web pages.
- Cadence: Low-latency, near-real-time retrieval.
- Failure points: Model hallucinations caused by stale context and a lack of source citations.
- Insight: The Model Context Protocol (MCP) now serves as a standard open-source bridge for connecting AI applications to external data systems securely.
For agentic workflows, view the Olostep AI platforms use case to see how web search acts as a backend primitive.
If you are building custom assistants, review the Olostep MCP server docs.
Common Data Sourcing Challenges
Treating sourcing merely as a "collection task" guarantees pipeline failure. Here is how we recommend addressing the most common hurdles.
1. The data quality crisis
- Symptom: Incomplete fields, duplicate records, and inconsistent formatting.
- Root cause: Lack of schema enforcement at the point of ingestion.
- Fix: Implement hard validation contracts before data lands in your warehouse. Stop letting bad records enter the system.
2. Data fragmentation and tool sprawl
- Symptom: Conflicting metric definitions and overlapping software tools.
- Root cause: Siloed departmental ownership.
- Fix: Centralize your data catalog. Audit and cut redundant vendor feeds.
3. Exploding scalability costs
- Symptom: Massive cloud compute bills and brittle one-off pipelines.
- Root cause: Overbuilding real-time streaming architectures for batch-level business problems.
- Fix: Match freshness to the actual decision speed. Downgrade non-critical pipelines to daily batch schedules.
4. Schema drift and source volatility
- Symptom: Downstream dashboards suddenly break.
- Root cause: An external API or webpage format changed without warning.
- Fix: Decouple extraction from transformation. Actively monitor payload shapes and set up automated alerts for structural drift.
5. Provenance and compliance risks
- Symptom: Legal teams halt an AI deployment.
- Root cause: Engineering cannot prove where the training data originated or if the company has the right to use it.
- Fix: Document data transformations thoroughly. Implement automated deletion and correction workflows to comply with strict frameworks like the EU AI Act.
Selecting Data Sourcing Tools
Avoid buying software before defining the exact architectural category you need. Look past the shiny objects.
Core tool categories
- Connectors and ingestion tools: Move payloads from source to destination (examples: Fivetran, Airbyte).
- Transformation and orchestration: Cleanse, join, and schedule data flows (examples: dbt, Airflow).
- Observability and quality: Monitor schema drift and pipeline uptime (example: Monte Carlo).
- Web data infrastructure: Manage the complex nuances of unstructured public web extraction.
Where a unified web data layer fits
When public web data makes up a large portion of your source mix, engineering teams typically stitch together custom scripts, rotating proxies, headless browsers, and brittle HTML parsers. A unified web data layer replaces this sprawling, high-maintenance infrastructure, delivering clean outputs directly to your analytics and AI systems.
Integrating Olostep
Olostep operates as an AI-first web data infrastructure platform. It provides a single API layer for search, scraping, crawling, structured parsing, and AI agent workflows. It is the optimal choice when you require scalable public web data, structured JSON payloads, or LLM-ready markdown.
/scrapes: Extracts real-time markdown, HTML, screenshots, or JSON./parsers: Converts unstructured pages directly into backend-compatible JSON./batches: Processes thousands of URLs asynchronously in a single job./answers: Grounds AI-generated responses with citations and structured formats./agents: Runs scheduled research tasks and outputs directly to your database.
Real-world proof: Companies like Merchkit rely on Parsers, Scrape, and Batch endpoints to standardize retailer product data at scale. Read how Merchkit automates catalog enrichment.
The Bottom Line: Start Small, Scale Trust
Data sourcing is not a mandate to collect every digital footprint available. It is a strict exercise in trust, fit, and operational repeatability. Treating data acquisition as an unregulated free-for-all guarantees downstream failures, exploding cloud costs, and unusable AI models.
Your actionable next steps:
- Define one specific business use case before touching any infrastructure.
- Audit your current sources to identify overlapping or broken endpoints.
- Cut one redundant source to reduce your maintenance overhead.
- Set one strict quality validation rule at the point of data ingestion.
If extracting and structuring external web data is part of your roadmap, explore Olostep's documentation to start building a reliable data sourcing strategy today.
FAQ
What is data sourcing?
Data sourcing is the complete operational process of finding, selecting, acquiring, ingesting, and validating data from internal and external origins. It ensures raw information is reliably formatted for business intelligence and AI models.
What are the different data sourcing methods?
Common methods include API integrations, Change Data Capture (CDC) for databases, file transfers (SFTP), webhooks, licensed data marketplaces, and automated web data extraction.
Why is data sourcing important?
It establishes the foundation for accurate decision-making. Poor sourcing results in broken engineering pipelines, inaccurate dashboards, hallucinating AI models, and severe compliance risks.
What is the difference between data sourcing and data ingestion?
Data sourcing is the entire strategic lifecycle of choosing, acquiring, and governing a dataset. Data ingestion is merely the technical act of moving that data from the source system into a target destination like a cloud warehouse.
How do you build a data sourcing strategy?
Start by scoping the exact business need. Next, optimize your source mix by prioritizing internal data first. Choose the right collection method based on required freshness, and enforce strict quality validation before the data enters your pipelines.