
Are you building a data pipeline or a legal liability? Every day, engineering teams deploy automated crawlers under the false assumption that if a webpage loads in a browser, the data is free for the taking. This mistake destroys startups and triggers massive class-action lawsuits. Before you write a single line of code, you need a defensible compliance framework.
Is web scraping legal? Yes, web scraping can be legal when extracting publicly accessible, factual data for internal use. However, web scraping can become illegal if you bypass authentication barriers, breach explicit website Terms of Service, extract protected personal data, or mass-download copyrighted material to train commercial AI models. Your legal risk depends entirely on your access method and downstream data usage.
Irresponsible data extraction carries immediate real-world consequences. In April 2025, the Wikimedia Foundation reported a 50% bandwidth surge from scraper bots pulling multimedia content for AI models. Legitimate automation requires strict discipline.
This guide provides a definitive Green, Yellow, and Red compliance framework to evaluate your risk before deployment.
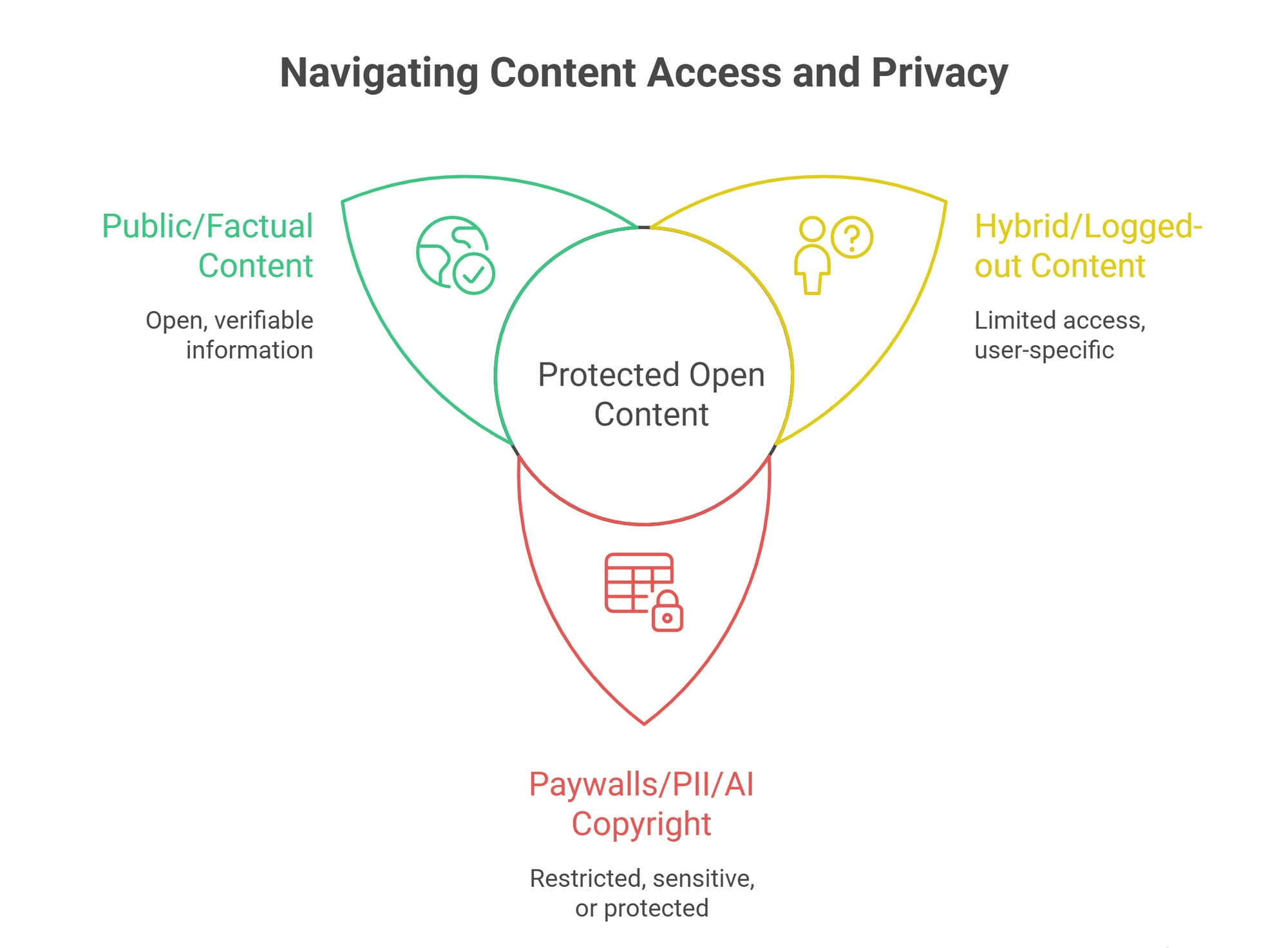
When Is Web Scraping Legal vs. Illegal?
Key Takeaway: Stop viewing web scraping as a single legal event. A compliant pipeline must survive two distinct legal tests: how you acquire the data and what you do with it.
The Two Legal Pillars: Collection vs. Reuse
Many data engineers falsely assume "publicly available" means "legally unrestricted." Scraping carries two distinct legal layers.
1. The Collection Layer: How did you get the data? Did you trespass on private servers? Did you bypass a CAPTCHA? Did you breach an explicit user agreement by scraping while logged in? Accessing data without logging in weakens certain breach-of-contract arguments. Bypassing a paywall practically guarantees liability.
2. The Reuse Layer: What happens to the payload? Getting the data safely does not give you ownership. If your end use violates copyright laws, trains competing generative AI models, or resells protected personal profiles, you face severe legal exposure regardless of how cleanly you extracted it.
Guidance like the U.S. Copyright Office's Part 3 Generative AI Training report, released in pre-publication form on May 9, 2025, signals that taking copyrighted expression to train directly competing AI models creates substantial infringement risk.
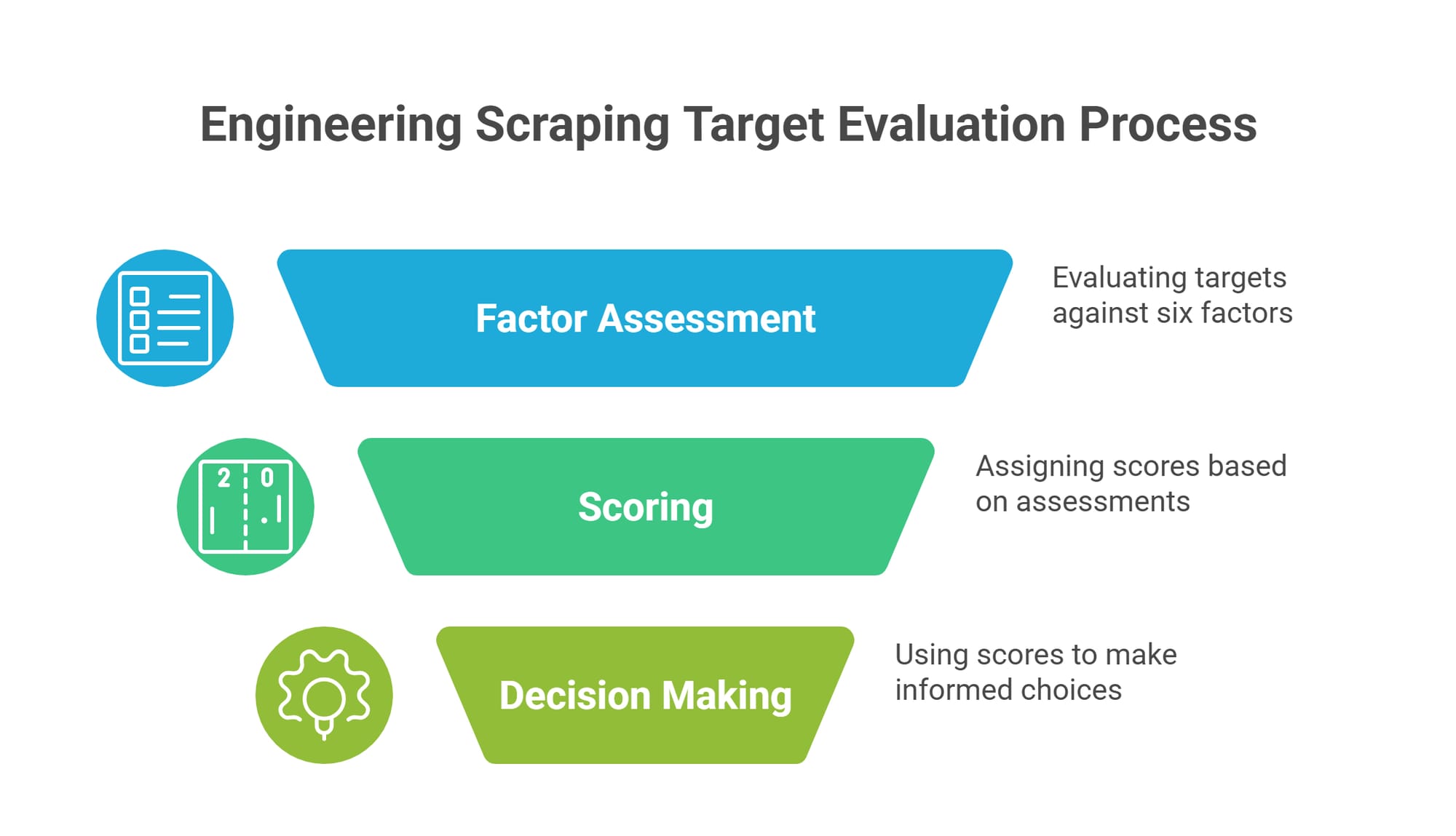
The 6-Factor Web Scraping Legality Checklist
Key Takeaway: Score your crawler against these six operational factors before launch. A single failure in any category escalates your legal risk from negligible to severe.
Do not wait for an IP ban to evaluate your pipeline. Use this framework to assess your risk profile.
- Access Method: Public, logged-out pages present the lowest risk. Authenticated spaces, paywalls, and API token environments trigger immediate contractual and anti-hacking laws.
- Terms of Service (ToS): Did you form a contract? Creating an account or clicking "I Agree" legally binds you to the site's rules. Violating those terms transforms a standard extraction job into a direct breach of contract.
- Data Payload Type: Factual fields like prices, dimensions, and dates carry lower copyright risk. Expressive content like articles, user reviews, and proprietary code carry high copyright risk.
- Personal and Biometric Data: Scraping names, emails, faces, or voiceprints triggers strict regulatory frameworks. The Clearview AI settlement, valued by the court at about $51.75 million and finally approved on May 12, 2025, showed that unconsented biometric scraping can create massive liability.
- Downstream Use: Internal analytics and price monitoring rarely cause disputes. Building a direct competitor, reselling the raw database, or training commercial AI models heavily escalates exposure.
- Operational Burden: Crawlers that send millions of concurrent requests degrade server performance. Aggressive traffic invites tort claims like "trespass to chattels" completely disconnected from the actual data payload.
Core Web Scraping Laws Governing Data Extraction
Key Takeaway: Web scraping compliance spans federal anti-hacking statutes, copyright protections, state privacy laws, and common-law contracts.
If your scraper touches sensitive data, you must understand the specific legal statutes that govern your actions.
The CFAA and Unauthorized Access
The Computer Fraud and Abuse Act (CFAA) serves as the US federal anti-hacking statute. It penalizes accessing a computer "without authorization." While accessing public data generally avoids CFAA violations, bypassing authentication or breaching secure API endpoints firmly violates this law.
DMCA Anti-Circumvention
When a site uses technological measures to protect its content (CAPTCHAs, tokenized access, IP rate limits) and you engineer a workaround, you risk violating Section 1201 of the Digital Millennium Copyright Act (DMCA).
Copyright Law: Facts vs. Expression
Copyright law protects original expression, not raw facts. Extracting a product's price or SKU is generally lower risk. Copying a detailed product description or proprietary imagery crosses into infringement.
Global Privacy Laws (GDPR, CCPA, BIPA)
Personal data changes everything.
- Scraping EU citizen data triggers the GDPR.
- Extracting California consumer data triggers the CCPA.
- Scraping facial recognition data without explicit consent triggers Illinois's severe BIPA statute.
Robots.txt Compliance Signals
Respecting robots.txt is standard good-faith engineering. It acts as an operational boundary. In jurisdictions like the EU, machine-readable opt-outs can also operate as formal rights reservations against text-and-data-mining for AI.
Landmark Web Scraping Cases Every Developer Should Know
Key Takeaway: Read legal precedents for their specific fact patterns. One ruling rarely answers every data collection scenario.
Core takeaway: The Ninth Circuit held that scraping publicly accessible data likely does not violate the CFAA. This is an important but narrow precedent. It protects against specific hacking claims but offers zero protection against copyright, privacy, or infrastructure burden lawsuits.
Thomson Reuters v. Ross Intelligence
Core takeaway: Downstream use matters. Ross used Westlaw headnotes to build a competing AI legal research tool. In February 2025, the court granted Thomson Reuters summary judgment on fair use for the headnotes at issue, underscoring how downstream AI training and direct commercial competition can sharply escalate copyright risk.
Ryanair DAC v. Booking Holdings Inc.
Core takeaway: Public logged-out access differs entirely from credentialed access. In July 2024, a Delaware jury found for Ryanair on a CFAA theory tied to the authenticated myRyanair environment; in January 2025, the court set aside the verdict because Ryanair did not prove the statute's $5,000 civil-loss threshold. The litigation still shows why credentialed access creates much higher risk than scraping public logged-out pages.
Legal Considerations for Web Scraping Use Cases
Key Takeaway: Your legal risk fluctuates wildly depending on what your product actually does with the extracted information.
Low-Risk Use Cases
- Price Monitoring: A highly legitimate application. Extracting public pricing facts for market research is generally lower risk, provided you enforce rate limits and avoid logged-in states.
- Internal Analytics: Keeping derived datasets internal for operational benchmarking is significantly safer than republishing them.
High-Risk Use Cases
- AI Training Datasets: Scraping expressive content to train generative models heavily implicates copyright law. The May 2025 U.S. Copyright Office Part 3 report signals that using unlicensed material to generate competitive expressive outputs is unlikely to qualify as fair use.
- Lead Generation: Scraping names, emails, and phone numbers triggers privacy frameworks (GDPR, CCPA) and often violates platform-specific anti-harvesting policies.
- Direct Commercial Resale: Harvesting a site's proprietary data to build a direct substitute product invites aggressive litigation.
Is Web Scraping Legal in the US vs. Europe?
Key Takeaway: Data flows across borders. Ensure you understand the specific compliance laws of the state or country where your target data originates.
Is web scraping legal in the US?
Yes, generally. US legal analysis revolves around the CFAA for access violations, common law for contract breaches, and federal copyright law. State laws like California's CCPA and Illinois's BIPA heavily overlay these federal rules when personal data is involved.
Is web scraping legal in the EU?
The EU operates under highly restrictive frameworks. Scraping personal data triggers the GDPR immediately. Additionally, the EU Digital Single Market (DSM) Directive allows rights holders to reserve text-and-data-mining rights using machine-readable means. If an EU site updates its robots.txt or similar signals to block AI scraping, ignoring that reservation can create direct legal consequences.
Engineering Safeguards: Ensuring Web Scraping Compliance
Key Takeaway: Legal safety requires strict technical implementation. You must control request rates, minimize payloads, and maintain precise audit logs.
Proper data governance must be engineered directly into your pipeline.
Pre-Scrape Configuration
- Define the strictly required fields and drop all unnecessary data points.
- Classify the data type (Fact, Expression, or PII).
- Ensure your access relies solely on a logged-out state.
Execution Safeguards
- Implement conservative rate limits and backoff logic.
- Identify your bot honestly via clear user-agent strings.
- Do not bypass technical controls or IP blocks.
- Run regex filters to drop standard PII (emails, phone numbers) at the ingestion layer before the data ever hits your database.
Auditability and Proof
In a legal dispute, you need documentation. Log the target robots.txt snapshot, the Terms of Service review date, your request configurations, and your automated deletion schedules.
If your team requires structured extraction workflows that reduce over-collection and keep automation pipelines predictable, Olostep provides batch processing APIs designed specifically for clean, audit-friendly web data pipelines.
How to Handle a Cease-and-Desist Letter
Key Takeaway: A cease-and-desist is a formal warning. Stop the operation immediately, preserve your logs, and assess your legal position objectively.
Ignoring a legal notice demonstrates willful disregard, escalating potential damages in court. Take the following steps:
- Pause the workflow: Halt the specific crawler mentioned in the letter immediately.
- Preserve evidence: Lock down your audit trails, request settings, internal review notes, and the state of the target's
robots.txtat the time of extraction. - Map the complaint: Run the complaint against the 6-factor framework above. Did you breach a login? Did you pull copyrighted expression?
- Escalate to counsel: Never rely purely on engineering judgment if the dispute involves personal data, AI model training, or bypassed paywalls.
FAQ: Popular Questions About Web Scraping Legality
Is scraping websites legal if the data is public?
Public access mitigates hacking claims under the CFAA, but it does not grant universal immunity. You still face severe legal exposure if you extract copyrighted content, collect personal data, or create massive server disruption.
When is web scraping illegal?
Web scraping becomes illegal when you bypass authentication barriers, breach explicit user contracts, copy protected expressive content for commercial AI training, or extract protected biometric data without explicit user consent.
Can you legally scrape data for AI training?
Training AI on scraped data introduces massive copyright risk. While extracting factual points is generally safer, scraping expressive content like articles, books, or code to train commercial generative models is currently the subject of heavy litigation and regulatory scrutiny.
Are Terms of Service legally binding for scrapers?
Yes. If you create an account, log in, or pass an authenticated API token to scrape a platform, courts generally enforce those Terms of Service as a binding contract.
Is ignoring robots.txt illegal?
Ignoring robots.txt is not a standalone federal crime in the US, but it serves as strong evidence of bad faith. In jurisdictions like the EU, machine-readable opt-outs can carry formal legal weight.
Final Takeaway: Responsible Automation Beats Risky Extraction
Is web scraping legal? Yes, provided you operate within strict, defensible boundaries. Publicly available data is a starting point, not a safe harbor.
To build sustainable web data pipelines, you must classify your access methods, segregate low-risk facts from high-risk expression, limit your collection payload, and maintain exhaustive audit logs of your operational behavior.
Disclaimer: This guide helps engineering and product teams assess compliance frameworks. It does not replace formal legal advice for high-risk data collection.
Download the compliance checklist and use it before launching a new scraper. If your team needs structured extraction workflows that reduce over-collection and keep automation pipelines predictable, Olostep provides secure infrastructure for modern data teams.