
Disclaimer: This section is informational, not legal advice.
Author note: As a data pipeline engineer, I evaluate extraction strategies based on production reliability and long-term maintenance, not local testing. This guide reflects real-world constraints from scaling infrastructure.
Building a robust pipeline forces an immediate architectural decision: should you use job scraping tools vs API endpoints? You need structured hiring data to power market intelligence, HR platforms, or AI models. However, target sites constantly change their DOM, and aggressive anti-bot systems block automated requests. I have seen too many engineering teams burn months building custom infrastructure, only to drown in daily maintenance. You must choose between owning the extraction infrastructure yourself or paying a vendor to handle it.
Direct Answer
When comparing job scraping tools vs APIs, scraping tools offer unlimited source flexibility but require heavy, ongoing engineering maintenance to bypass anti-bot protections and fix broken parsers. Conversely, a job scraping API delivers clean, structured JSON instantly and handles proxy management behind the scenes, offering higher reliability at a predictable cost. Choose scraping tools for highly customized, niche coverage; choose APIs for fast, scalable, maintenance-free data ingestion.
The Core Problem: Why Extraction is Hard
Raw HTML holds no value without context. Your collection method dictates data freshness, pipeline reliability, and downstream product quality.
Job boards deploy intense anti-bot pressure to protect their inventory. Automated bot traffic reached 51% of all web traffic in 2024, meaning data extraction is an ongoing arms race. Depending on your product, your extraction needs differ:
- Job boards: Require broad coverage, high freshness, and strict deduplication.
- Market intelligence: Demands accurate, longitudinal trend tracking across geographies.
- HR tech platforms: Need seamless workflow automation and structured normalization.
- AI training: Requires clear data provenance, semantic cleanliness, and repeatable collection.
Job Scraping Tools Comparison: Control vs Convenience
Scraping tools maximize control. APIs maximize speed-to-value. Your target source usually dictates project success far more than the parser you deploy.
Defining job data scraping tools
Custom crawlers, browser automation libraries (like Playwright or Selenium), and open-source frameworks fall into this bucket. You execute local or cloud code to retrieve, render, and extract data. You control the routing, the headers, and the parsing logic.
Defining a job scraping API
APIs provide structured data via programmatic endpoints. This category splits into official partner APIs (like Indeed or LinkedIn partner access) and third-party extraction APIs. They abstract away the browser rendering and deliver clean JSON.
Reliability: Job Scraping API vs Scraper in Production
APIs provide stability at the interface layer. Scraper reliability plummets as target hardness and anti-bot pressure increase.
Evaluate reliability operationally. Breakage is inevitable; the defining metric is how quickly your team recovers when a target site pushes an update.
Why custom scrapers fail
Site structure changes: Target sites frequently push DOM changes and rotate class names to break naive parsers. Pagination logic breaks unexpectedly, leaving massive gaps in your dataset.
Anti-bot protections: Scraping operates inside a hostile environment. Strict rate limits, browser fingerprinting, and CAPTCHA challenges break extraction logic instantly. Advanced bot protection is now common on high-value targets.
Infrastructure limits: Scraping job boards at scale requires massive engineering bandwidth. You must maintain browser fleets, optimize retry logic, and monitor proxy health daily. Independent benchmarks on protected targets show how brittle this gets: in Proxyway's comparison, Indeed averaged an 81.4% success rate across tested scraping APIs, with one participant failing more than 80% of requests.
Why APIs win on reliability
APIs deliver predictable data shapes. A stable schema guarantees cleaner ingestion and eliminates middle-of-the-night engineering alerts for broken parsers. You completely remove browser maintenance and proxy management from your sprint planning.
However, APIs introduce vendor dependencies. You face coverage gaps, rate limits, and unilateral deprecations. Official platforms often tie API access to high sponsorship spend and strict usage policies.
Cost: Sticker Price vs Total Cost of Ownership
Self-built scraping looks cheap until you factor in engineering salaries, proxy spend, and normalization workflows. APIs look expensive upfront but drastically reduce Total Cost of Ownership (TCO).
List prices deceive data teams. You must evaluate pipeline economics through the lens of TCO.
The hidden costs of building
- Network expenses: Premium residential proxy pools and regional routing cost thousands of dollars monthly. Blocked requests waste bandwidth and inflate bills.
- Engineering salaries: Engineers spend weeks on parser fixes and anti-bot workarounds. The U.S. Bureau of Labor Statistics lists median pay for software developers at $133,080 per year in May 2024, so even one dedicated maintainer quickly becomes a six-figure operating cost.
- Data normalization: Raw text extraction forces you to build taxonomy mapping, deduplication logic, and stale job filtering.
API economics
Vendors charge for successful requests, concurrency, and structured output. While you risk monthly overages, you eliminate dedicated scraper maintenance. Industry benchmarks estimate a 24-month build TCO for custom aggregation pipelines at upwards of $700K to $1M, largely driven by engineering salaries dwarfing server costs.
Compliance: Friction and Legal Risk
Using an API shifts technical burden, but you retain legal responsibility. Compliance depends heavily on your target source, technical behavior, and downstream data usage.
Do not treat public web access as a blanket legal defense for unrestricted data mining. Verify these risk vectors before you write a single line of code:
- Terms of Service (ToS) and contractual limits.
- Public vs. authenticated access barriers.
- Personal Data (PII) minimization.
- Downstream commercial redistribution rights.
Assessing source risk
- Official APIs: Lowest risk. You remain constrained by explicit platform terms.
- Public career pages: Low technical risk, but requires active ToS review and responsible crawl rates.
- Login-gated sources: Highest risk. Never scrape authenticated accounts without explicit contractual authorization.
The Ninth Circuit opinion in hiQ Labs v. LinkedIn clarified a narrow CFAA question regarding public pages. It did not eliminate contractual ToS exposure, copyright obligations, or technical circumvention risks. Involve legal counsel early if your product commercially redistributes listings.
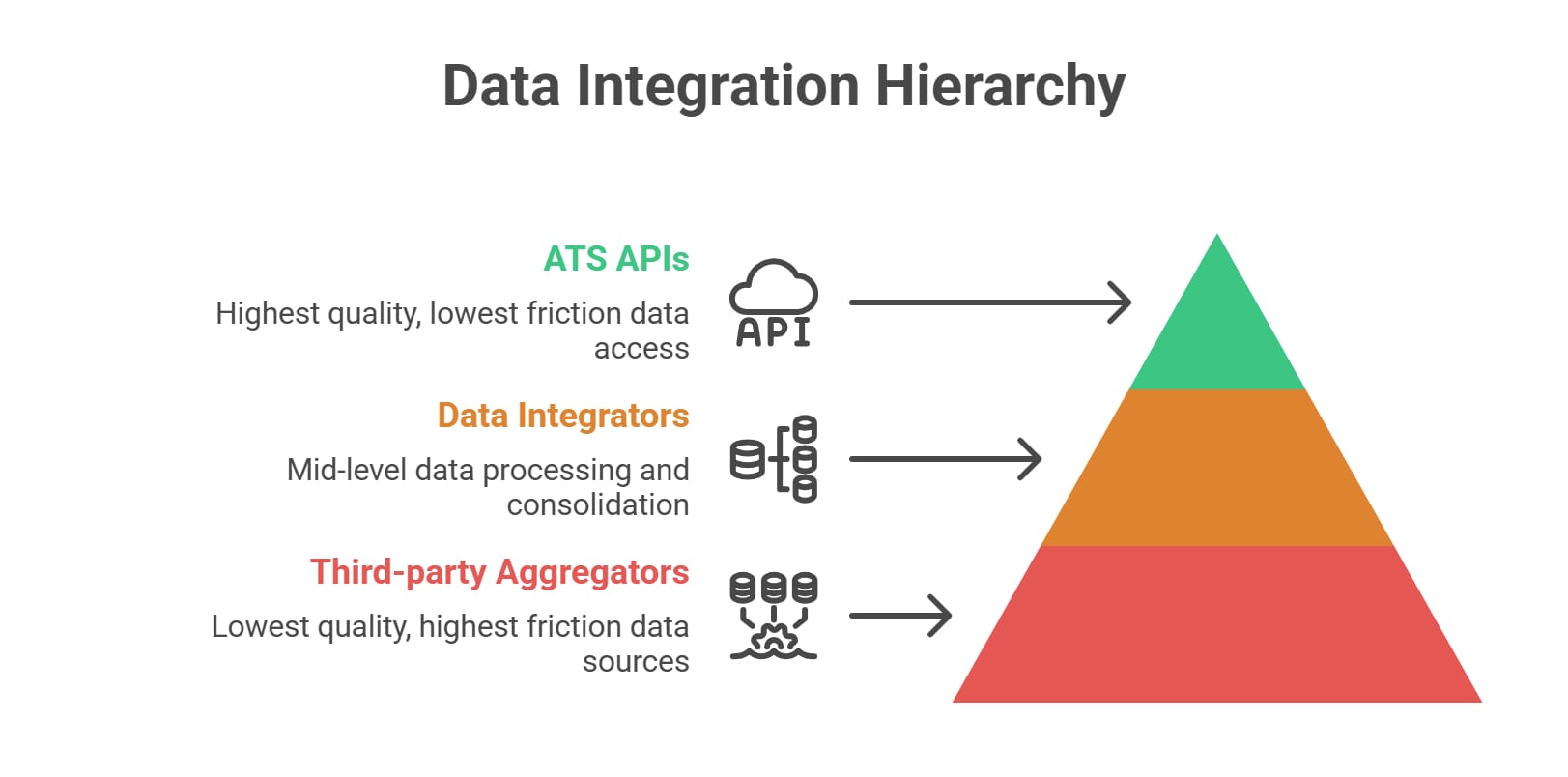
The Overlooked Strategy: ATS-First Sourcing
Stop choosing tools before choosing sources. Shifting your collection from third-party aggregators to first-party employer career pages dramatically improves data quality.
Company sites deliver a massive source-of-truth advantage. You capture fresher postings with zero ghost jobs. These endpoints apply lower anti-bot pressure and frequently support easy structured extraction natively.
Many Applicant Tracking Systems (ATS) expose raw job data via public GET endpoints without authentication. Widespread adoption of Schema.org JobPosting tags standardizes fields automatically. This approach proves ideal for high-quality aggregators and AI products demanding exact provenance. It requires mapping fragmented schemas, but the data quality return on investment is massive.
How to Scrape Job Postings: A Decision Framework
Assess your need for breadth, your tolerance for infrastructure maintenance, and your time-to-market constraints.
There is no universally correct architecture. Base your pipeline strategy on your product constraints:
- Building a job aggregator? Start with career pages and ATS sources for listing validity. Use APIs for major boards to avoid proxy wars.
- Building a hiring analytics platform? Prioritize consistent, normalized inputs. A job listings scraping API beats raw crawling for stable historical trend analysis.
- Building an AI or research tool? Optimize heavily for provenance and rights of use. Stick to source-first collection.
The 10-Second Decision Flow:
- Need the fastest launch? Go API-first.
- Need the widest coverage? Deploy a mixed strategy (APIs + Custom Scrapers).
- Highly sensitive compliance profile? Target Career-pages/ATS natively.
- Possess dedicated infrastructure engineers? Build custom scrapers.
FAQ
What is the difference between a job scraping tool and a job scraping API?
A job data scraping tool requires you to write extraction logic, manage proxies, and maintain parsers. An API abstracts this entirely, executing the extraction behind the scenes and returning clean, structured JSON natively.
How do you scrape job postings at scale without constant breakage?
To scrape job postings reliably at scale, shift your focus from raw scripts to intelligent target selection. Prioritize public ATS API endpoints or leverage vendor APIs that handle proxy rotation and browser fingerprinting automatically to bypass major board friction.
Is a job listings scraping API better than Playwright or Selenium?
A job scraping API vs scraper comparison favors the API if you want speed and clean ingestion. Playwright gives you ultimate rendering control but forces your team to manage costly browser infrastructure, proxy health, and constant DOM updates.
Can you scrape LinkedIn jobs or other job boards legally?
Never treat public access as a blanket legal pass for scraping linkedin jobs or job boards. Always consult legal counsel, respect platform Terms of Service, avoid bypassing authentication barriers, and strictly minimize personal data collection.
What is the cheapest way to collect job market data?
Self-built tools cost the least in raw cloud compute but generate massive hidden engineering expenses. The truly cheapest method depends on your volume requirements; APIs often win on long-term Total Cost of Ownership by eliminating maintenance salaries.
Bottom Line
Your technical strategy defines your product's operational overhead.
- Scraping tools give you absolute control, but you immediately inherit parser breakage, proxy routing costs, and continuous maintenance.
- APIs drastically reduce engineering overhead, delivering structured data faster, though they introduce vendor dependencies.
- ATS-first sourcing provides the best balance of reliability and compliance for serious builders.
If you want API-first infrastructure that can search, extract, batch, and structure job-page data into JSON without running crawler infrastructure yourself, Olostep fits perfectly. It gives your data pipelines the scale of an enterprise crawler with the clean integration of a single endpoint.
Ultimately, winning the job scraping tools vs API debate comes down to mapping your exact target sources, understanding your compliance posture, and honestly evaluating your internal engineering bandwidth.