
A Google Shopping scraper is an automated tool that extracts product data—prices, seller information, reviews, and specifications—directly from Google's search results. For any e-commerce business, this isn't just a niche tech gadget; it's a critical tool for market intelligence, enabling data-driven pricing strategies and a significant competitive advantage.
However, building a scraper that reliably bypasses Google's sophisticated anti-bot measures is a major challenge. Frequent IP blocks, CAPTCHAs, and dynamic HTML structures can render a simple script useless in minutes. This guide will walk you through the common pitfalls, compare different scraping approaches, and provide a step-by-step solution for building a resilient scraper using Python and the Olostep API.
Why Your E-commerce Business Needs a Scraper

In the hyper-competitive world of e-commerce, manually tracking competitors' prices and product catalogs is not just inefficient—it's impossible. The market data shifts too quickly, and the volume is overwhelming. Relying on manual checks means you're always playing catch-up, making decisions based on outdated information. This is where a Google Shopping scraper fundamentally changes the game.
The Problem with Manual Data Collection
Think about the sheer scale for a second. A single search can return hundreds of products from dozens of sellers. Trying to copy and paste all that data manually isn't just painfully slow; it's a recipe for costly errors. An automated scraper, on the other hand, can extract thousands of data points in minutes with perfect accuracy.
The table below breaks down just how stark the difference is.
Manual vs. Automated Google Shopping Data Collection
| Metric | Manual Collection | Automated Scraper |
|---|---|---|
| Speed | Excruciatingly slow. Hours for a few dozen products. | Lightning fast. Thousands of data points in minutes. |
| Accuracy | Prone to human error (typos, missed data). | 100% accurate and consistent every time. |
| Scale | Impossible to scale beyond a handful of competitors. | Can monitor the entire market with ease. |
| Data Richness | Limited to what you can see and copy-paste. | Extracts comprehensive data fields automatically. |
| Frequency | Infrequent checks due to the time commitment. | Can run continuously for real-time insights. |
| Strategic Value | Provides a snapshot, leading to reactive decisions. | Enables proactive strategy and trend analysis. |
As you can see, there's really no contest. Manual methods keep you stuck in the past, while automation opens the door to truly data-driven strategy.
Two Approaches to Building a Scraper
When it comes to building a Google Shopping scraper, you generally have two options:
-
The DIY Approach (e.g., Selenium/Playwright): This involves writing a script that automates a real web browser to navigate to Google Shopping, enter a search query, and parse the resulting HTML.
- Pros: Full control over the scraping logic.
- Cons: Extremely brittle. You're responsible for managing a massive pool of high-quality proxies, solving CAPTCHAs, mimicking human browser fingerprints, and constantly updating your code when Google changes its layout. This approach is complex, costly, and unreliable at scale.
-
Using a Third-Party Scraping API: This involves sending a simple request to a specialized service that handles all the complexities of web scraping for you. The API manages proxies, solves CAPTCHAs, and returns clean, structured data.
- Pros: Highly reliable, scalable, and easy to implement. You can focus on analyzing data instead of maintaining a fragile scraper.
- Cons: Incurs a cost, though it's often far less than the cost of building and maintaining a DIY solution.
For any serious application, using a dedicated API is the superior approach. It offloads the entire cat-and-mouse game of anti-bot circumvention, providing a stable and predictable way to get the data you need.
Key Takeaway: The goal isn't just about grabbing data. It's about getting it consistently and at a scale that matters. Automation transforms raw data from a chore into a reliable stream of business intelligence that actually fuels growth. E-commerce businesses are using Google Shopping scrapers to pull massive amounts of product data like pricing, titles, and images. For example, even a basic scraper can pull up to 100 products per keyword search, which gives store owners a powerful dataset for price analysis. As experts at ScraperAPI explain when you scrape Google Shopping results, using an API is really the only reliable way to do this for modern e-commerce intelligence.
Building a Resilient Google Shopping Scraper: A Step-by-Step Guide
Alright, let's switch from theory to actually building a working Google Shopping scraper. We'll walk through a complete Python script you can copy, paste, and run. It uses the popular requests library to interact directly with the Olostep API, demonstrating a robust and production-ready approach.
For this walkthrough, we'll use a real-world example: scraping product results for "running shoes." The mission is simple: send a request to Olostep and get back a tidy, structured JSON file packed with product titles, prices, sellers, and links.
Step 1: Set Up Your Environment
Before we jump into the code, you only need two things: Python installed on your machine and the requests library. If you don't already have requests installed, open your terminal and run this command:
pip install requestsNext, you'll need an Olostep API key. You can get one by signing up for a free account on the Olostep website. Once you have it, store it securely, for example, as an environment variable. We'll need it to authenticate our API calls.
The entire process we're about to code is beautifully simple, as this graphic shows.
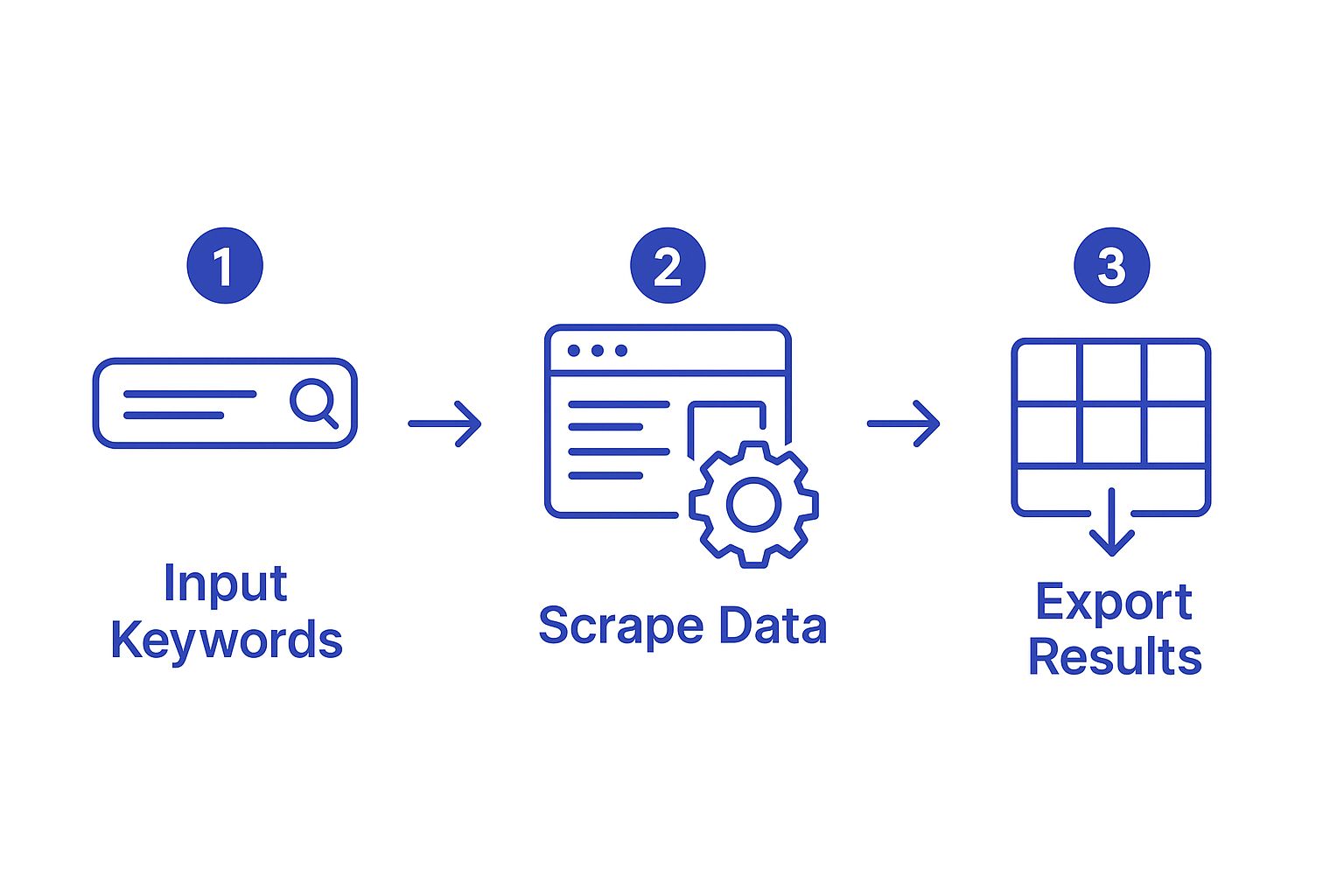
This workflow is the core of what we're doing: turning a simple keyword into a structured dataset ready for analysis.
Step 2: Construct and Send the API Request
We’re going to send a POST request to Olostep's API endpoint at https://api.olostep.com/v1/scrapes. The body of our request will be a JSON payload that tells the API exactly what we want to scrape.
Here’s the full Python script. You can save this as a .py file, replace 'YOUR_API_KEY' with your actual key, and run it.
import requests
import json
import os
# Best practice: Load API key from environment variables
api_key = os.getenv('OLOSTEP_API_KEY', 'YOUR_API_KEY')
# API endpoint
url = 'https://api.olostep.com/v1/scrapes'
# Request headers with authentication
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json'
}
# The payload defining our scraping job for "running shoes" in the US
payload = {
"url": "https://www.google.com/search?tbm=shop&q=running+shoes",
"country": "us",
"output_format": "json"
}
try:
# Making the POST request to the Olostep API with a 30-second timeout
response = requests.post(url, headers=headers, json=payload, timeout=30)
# Raise an exception for bad status codes (4xx or 5xx)
response.raise_for_status()
# Parse the JSON response
data = response.json()
# Pretty-print the full JSON response to inspect the structure
print("--- Full API Response Payload ---")
print(json.dumps(data, indent=2))
# Example of extracting and printing specific product details
print("\n--- Extracted Product Data ---")
if data.get('data') and data['data'].get('shopping_results'):
for product in data['data']['shopping_results']:
title = product.get('title')
price = product.get('price')
source = product.get('source')
print(f"Title: {title}\nPrice: {price}\nSource: {source}\n---")
else:
print("No shopping results found in the response.")
except requests.exceptions.HTTPError as http_err:
print(f"HTTP error occurred: {http_err} - {response.text}")
except requests.exceptions.RequestException as err:
print(f"An error occurred: {err}")This script takes our search for "running shoes" and sends it to Google Shopping through Olostep's infrastructure, specifically targeting the US market ("country": "us"). If you need to target other Google services, our guide on the Olostep Google Search Scraper is a great place to learn more.
Step 3: Understand the API Response
Once you run the script, you'll see a complete JSON response printed in your console. This is the raw, structured data fresh from the API. The most important part for us is the shopping_results array, which contains individual product listings.
Here’s a sample of what an entry for a single product looks like inside the response payload:
{
"title": "Nike Men's Revolution 7 Running Shoes",
"price": "$70.00",
"extracted_price": 70.0,
"source": "DICK'S Sporting Goods",
"product_link": "https://www.google.com/shopping/product/...",
"thumbnail": "https://encrypted-tbn0.gstatic.com/shopping?q=...",
"rating": 4.5,
"reviews": 120,
"shipping": "Free shipping",
"product_id": "1234567890"
}By parsing this JSON, you can grab critical data points like the product title, its price, and the seller (source) with no fuss. This is the magic of using an API—it turns messy HTML into clean, usable data that’s ready for your spreadsheets, databases, or analytics tools.
Key Insight: Using an API like Olostep is a game-changer because it handles all the messy background work—managing proxies, solving CAPTCHAs, and rendering JavaScript. You just send a simple request and get clean data back, letting you focus on your analysis instead of constantly fixing a broken scraper.
Dealing With Anti-Scraping Defenses and Errors

Getting blocked is part of the game when scraping a target as sophisticated as Google. To build a truly resilient Google Shopping scraper, you must plan for failure. This means anticipating and gracefully handling the defenses Google has in place to shut down automated traffic.
Common Anti-Bot Defenses
Google employs a whole arsenal of anti-bot technologies:
- Rate Limiting: Blocking requests from a single IP address that exceed a certain threshold.
- CAPTCHAs: Presenting challenges that are easy for humans but difficult for bots to solve.
- Browser Fingerprinting: Analyzing headers, JavaScript execution environment, and other signals to determine if a request is from a real user or a script.
- IP Blocking: Temporarily or permanently banning IP addresses that exhibit bot-like behavior.
Managing this on your own requires a large, high-quality proxy pool, sophisticated browser emulation, and automated CAPTCHA-solving services. It's a full-time engineering effort that distracts from your core goal: analyzing data.
Troubleshooting Common Failures
- CAPTCHAs: If you're building a DIY scraper, you'll eventually hit a CAPTCHA. The only solution is to integrate a third-party solving service like 2Captcha, which adds complexity and cost.
- 403 Forbidden / 429 Too Many Requests: These HTTP status codes indicate that your IP has been flagged or rate-limited. You need to rotate your proxy and adjust your request headers to appear more human.
- 5xx Server Errors: These suggest a temporary issue on Google's end. The best strategy is to wait and retry the request after a short delay.
- Timeouts: Your request may time out due to network issues or slow proxy speeds. Implementing a reasonable timeout and retry logic is essential.
Implementing Robust Error Handling and Retries
To make your scraper dependable, it can't crash at the first sign of trouble. Good error handling lets your script react intelligently when things go wrong. Let's build a more resilient request function in Python with retries and exponential backoff.
import requests
import time
def make_resilient_request(url, headers, payload, max_retries=3):
"""
Makes a POST request with error handling and exponential backoff for server-side errors.
"""
for attempt in range(max_retries):
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
# Success on 2xx status codes
if response.status_code == 200:
return response.json()
# Client-side errors (e.g., 401, 403, 429) - Retrying is often futile
elif 400 <= response.status_code < 500:
print(f"Client Error: {response.status_code} - {response.text}. Stopping retries.")
break
# Server-side errors (e.g., 500, 503) - These are worth retrying
elif 500 <= response.status_code < 600:
print(f"Server Error: {response.status_code}. Retrying...")
# Fall through to the retry logic below
except requests.exceptions.Timeout:
print("Request timed out. Retrying...")
except requests.exceptions.RequestException as e:
print(f"An unexpected request error occurred: {e}. Retrying...")
# Exponential backoff: wait 1s, 2s, 4s...
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Waiting {wait_time} seconds before next attempt.")
time.sleep(wait_time)
print("All retries failed.")
return None
# Example usage (replace with your actual request details)
# result = make_resilient_request(url, headers, payload)
# if result:
# print("Request successful!")This function introduces a retry loop with exponential backoff, a critical strategy. Instead of hammering the server immediately after a failure, it waits for an increasingly longer period.
Key Takeaway: You should build retry logic for transient errors like timeouts and 5xx (Server Error) codes. However, for 403 (Forbidden) or 429 (Too Many Requests), retrying from the same IP is usually pointless. This indicates a more serious block, which is precisely the problem that a professional scraping API solves for you.
To dive deeper into these strategies, learn more about how to scrape without getting blocked in our detailed guide.
Structuring and Analyzing Scraped Product Data
Getting raw JSON from a Google Shopping scraper is a great start, but it's only half the battle. The real value comes from structuring that data for analysis. This is where you transform a stream of information into a strategic asset for comparing competitor prices, tracking product availability, and spotting market trends.
From Raw JSON to a Structured Pandas DataFrame
For anyone working with data in Python, the go-to library is Pandas. A Pandas DataFrame is essentially a powerful, in-memory table that makes data manipulation and analysis incredibly straightforward. It's the perfect tool for taming the raw JSON response from the Olostep API.
Let's expand our script to parse the JSON and load the shopping_results directly into a DataFrame.
import requests
import json
import pandas as pd
# Assume 'data' is the JSON response from the Olostep API
# For demonstration, let's use a sample dictionary from a successful API call
data = {
"data": {
"shopping_results": [
{"title": "Nike Air Zoom Pegasus 40", "price": "$130.00", "extracted_price": 130.0, "source": "Nike Store"},
{"title": "Brooks Ghost 15", "price": "$140.00", "extracted_price": 140.0, "source": "Zappos"},
{"title": "HOKA Clifton 9", "price": "$145.00", "extracted_price": 145.0, "source": "Fleet Feet"}
]
}
}
# Extract the list of products from the response
product_list = data.get('data', {}).get('shopping_results', [])
if product_list:
# Load the list of dictionaries directly into a Pandas DataFrame
df = pd.DataFrame(product_list)
# Optional: Clean up and structure the data
df['price'] = df['extracted_price'] # Use the clean numeric price
df = df[['title', 'price', 'source']] # Select and reorder columns
print("--- Pandas DataFrame ---")
print(df)
else:
print("No shopping results found in the response.")That one line—pd.DataFrame(product_list)—instantly transforms a list of JSON objects into a clean, organized table ready for analysis.
Exporting Your Data to CSV
Once your data is in a DataFrame, exporting it to a shareable format is simple. A CSV (Comma-Separated Values) file is the universal language of data, easily opened in Excel or Google Sheets.
Just add one more line to the script to save the DataFrame to a file named google_shopping_data.csv.
# Assuming 'df' is the DataFrame we created earlier
if 'df' in locals() and not df.empty:
df.to_csv('google_shopping_data.csv', index=False)
print("\nData successfully exported to google_shopping_data.csv")The index=False argument is important; it prevents Pandas from writing its own row numbers into the CSV, keeping the output clean.
Key Takeaway: The workflow is refreshingly simple: scrape the data with an API, parse the JSON, load it into a Pandas DataFrame, and export it to a CSV. In just a few lines of code, you've turned raw API output into a usable business asset. Building a repository of historical price data is a cornerstone of competitive pricing. We've seen advanced systems monitor over 1,000 product SKUs hourly to predict competitor promotions and react to market shifts. You can learn more on the ShoppingScraper blog about historical price data.
Choosing The Right Scraping API For Your Project

Your scraping API is the engine of your data operation. Choosing the wrong one leads to unreliable data, frequent failures, and wasted budget. When building a Google Shopping scraper, the stakes are even higher due to Google's robust defenses.
Core Evaluation Criteria
Cut through the marketing noise and focus on what truly matters:
- Reliability & Success Rate: Does the service consistently deliver data, or is it plagued by errors? A 99%+ success rate should be your baseline.
- CAPTCHA & Block Management: How effectively does the API handle Google's anti-bot measures? A great API makes this entire problem invisible to you.
- Geotargeting Accuracy: Can you reliably request data as if you're browsing from a specific country or region? This is crucial for accurate pricing and availability.
- Pricing Model: Does the cost structure align with your usage? Pay-as-you-go models are great for starting out, while subscriptions offer better value at high volume.
Comparing Top Scraping APIs
Let's put a few major players side-by-side. The best fit depends on your specific needs. You can get a wider view in our guide to the top scraping tools available today.
Google Shopping Scraper API Comparison
This table breaks down how Olostep compares to other leading services like ScrapingBee, Bright Data, and ScraperAPI.
| Feature | Olostep | ScrapingBee | Bright Data | ScraperAPI |
|---|---|---|---|---|
| Primary Focus | Structured JSON for AI & developers | General web scraping, JS rendering | Large-scale enterprise data collection | Simplified API for web content |
| Proxy Quality | High-quality residential & datacenter | Good, with residential proxies | Extensive, market-leading network | Large, mixed-quality proxy pool |
| CAPTCHA Solving | Fully integrated and automatic | Included, performance varies | Advanced, part of their proxy manager | Integrated, reliable for most sites |
| Pricing Model | Credit-based, pay-as-you-go | Subscription-based | Enterprise-focused, complex pricing | Subscription-based by API calls |
| Ease of Use | Very high, simple POST request | High, well-documented API | Moderate, more complex setup | Very high, simple GET request |
The takeaway is that there's no single "best" tool for everyone. The right choice depends on your project's scale, budget, and technical requirements.
Key Insight: While a service like Bright Data offers immense power for enterprise-level projects, it comes with complexity. Olostep is built for developers and AI startups who need clean, structured data without a complicated setup. It hits the sweet spot between power, ease of use, and a straightforward pricing model.
Ethical and Legal Considerations
When scraping any website, it's crucial to act ethically and be aware of the legal landscape.
- Legality: Scraping publicly available data is generally considered legal in many jurisdictions, including the US, following landmark court cases like hiQ Labs v. LinkedIn. However, this does not give you a free pass to scrape irresponsibly.
- Terms of Service: Google's Terms of Service prohibit automated access. While violating ToS is not illegal, it can result in being blocked. Using a professional API helps navigate this by routing requests through a large network of proxies, making the traffic appear organic.
- Ethical Guidelines:
- Do not scrape personal data. Stick to public product and pricing information.
- Do not overload the website's servers. A good API manages request rates to avoid impacting the target site's performance.
- Respect
robots.txtas a guideline, but understand that for commercial data collection, it is often bypassed. A professional service will do this responsibly.
Final Checklist and Next Steps
You're now equipped to build a powerful Google Shopping scraper. Here’s a final checklist to ensure success:
- Define Your Goal: Clearly identify the data points you need (e.g., price, seller, ratings).
- Choose Your Tool: Select a reliable scraping API like Olostep to handle anti-bot challenges.
- Set Up Your Environment: Install Python and the
requestslibrary. - Build Your Script: Write a Python script to send a request with the correct payload and headers.
- Implement Error Handling: Add try/except blocks and retry logic for robustness.
- Parse and Structure Data: Use Pandas to convert the JSON response into a clean DataFrame.
- Store Your Data: Export the DataFrame to a CSV or load it into a database for analysis.
Next Steps:
- Automate Your Script: Set up a cron job or a cloud function (e.g., AWS Lambda) to run your scraper on a schedule.
- Visualize Your Data: Use tools like Matplotlib, Seaborn, or a BI platform like Tableau to create dashboards for price tracking and competitor analysis.
- Expand Your Scope: Apply these principles to scrape other e-commerce sites or different sections of Google.
Ready to stop wrestling with blocks and start getting clean, structured product data? Olostep handles the entire scraping process, delivering reliable Google Shopping data directly to your application. Get started with 500 free credits and build your scraper in minutes.


