
Welcome to the only Python web scraping guide you'll need in 2025. The problem is clear: the modern web is a vast, unstructured goldmine of data, but accessing it at scale is incredibly difficult. Manually copying product prices, stock levels, or market trends is impossible. Web scraping is the solution, and this tutorial will show you exactly how to do it effectively using Python.
We'll start by exploring basic methods with libraries like Requests and BeautifulSoup, which work for simple sites but quickly fail against modern web technologies. We will then build a robust, step-by-step solution using the Olostep API to overcome these challenges, ensuring you can extract data from even the most complex, JavaScript-heavy websites without getting blocked.
The Problem: Why Web Scraping is Essential (and Hard)
Every single day, an unbelievable amount of new data floods the internet. We're talking about numbers so large they're hard to grasp—projections estimate we'll hit over 394 zettabytes by 2028. This data, everything from product prices and stock levels to news articles and market sentiment, is a goldmine for anyone who can access it.
But there's a catch. Most of this valuable information is just sitting there, unstructured, inside the HTML of countless web pages. Web scraping is how you unlock it. The real problem scraping solves is one of scale and efficiency. Manually copying data from even a dozen pages is a nightmare. Trying to do it for hundreds or thousands is simply impossible. This is where you automate repetitive tasks and let the machine do the heavy lifting.
However, the web has evolved. Modern sites use sophisticated anti-bot measures, dynamic JavaScript rendering, and complex network protocols, making simple scrapers obsolete. This is the core challenge we'll solve.
Why Python is the Go-To Language for Web Scraping
So, why has Python become the default language for this? It really comes down to a few key strengths that make it perfect for data work.
- It’s Simple and Readable: Python’s syntax is clean and intuitive, almost like reading plain English. This means you can write a powerful scraper with less code than in other languages.
- A Massive Ecosystem of Libraries: This is the big one. Python has a vast collection of specialized libraries (
Requests,BeautifulSoup,Scrapy) that handle all the tricky parts of web scraping for you. - Incredible Community Support: Because Python is so popular, there's a huge community of developers out there. If you hit a roadblock, a quick search will almost always turn up a solution.
For anyone just starting out, Python provides the quickest and most direct path from a simple idea to a working data scraper. The entire ecosystem is built around data, making it a natural choice for developers, analysts, and data scientists.
Comparing Approaches: From DIY Scripts to Managed APIs
Before we build our solution, let's look at the common approaches to web scraping and their trade-offs.
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| DIY (Requests + BeautifulSoup) | Full control, great for learning, no cost. | Fails on JS-heavy sites, easily blocked, requires manual proxy/header management. | Simple, static websites and educational projects. |
| Headless Browsers (Selenium/Playwright) | Handles JavaScript rendering perfectly, can simulate user actions. | Slow, resource-intensive, complex to set up and maintain, still prone to blocking. | Scraping highly interactive sites or when browser automation is needed. |
| Web Scraping APIs (Olostep, etc.) | Handles proxies, JavaScript, and CAPTCHAs; highly scalable and reliable. | Involves a third-party service, has associated costs. | Professional, large-scale projects where reliability and avoiding blocks are critical. |
For this tutorial, we will start with the DIY approach to understand the fundamentals and then graduate to a professional API-based solution to build a scraper that works in the real world.
Setting Up Your Python Scraping Environment
A messy development environment is a recipe for disaster. Before writing any code, we must get our workspace set up correctly. This foundational step will save you from a world of dependency headaches down the road.
First things first, you need Python. If you don't have it, you can grab the latest version from the official Python website. During installation on Windows, check the box that says "Add Python to PATH" to simplify running Python from your command line.
Why You Must Use a Virtual Environment
With Python installed, our next move is creating a virtual environment. Think of it as a pristine, isolated sandbox just for this one project. It walls off the libraries for this specific scraper from every other project on your machine, which is critical for avoiding version conflicts. This is a non-negotiable best practice.
Creating one is simple. Open your terminal, navigate to your project folder, and run one of these commands:
# For macOS/Linux
python3 -m venv scraping-env
# For Windows
python -m venv scraping-envThis command creates a new folder called scraping-env. To use this sandbox, you have to activate it.
# For macOS/Linux
source scraping-env/bin/activate
# For Windows
scraping-env\Scripts\activateYou'll know it's working when (scraping-env) appears at the beginning of your command line prompt.
Installing Essential Libraries
Now that our environment is active, we can install the two workhorses of our scraping toolkit: requests and beautifulsoup4.
requests: An elegant and simple HTTP library for Python, built for human beings. It allows you to send HTTP/1.1 requests with ease.beautifulsoup4: A library for pulling data out of HTML and XML files. It creates a parse tree from page source code that can be used to extract data in a hierarchical and more readable manner.
Install both at once with a single pip command:
pip install requests beautifulsoup4Pro Tip: Always create a
requirements.txtfile to track your project's dependencies. It lets you (or anyone else) perfectly replicate your setup later. Just runpip freeze > requirements.txtto generate it.
Your environment is now perfectly configured. You're ready to start fetching and parsing web pages.
Step 1: Building a Basic Scraper with Requests and BeautifulSoup
Alright, with your environment set up, it's time to write some code. We're going to build your very first web scraper from the ground up. The goal is simple but practical: we'll pull real product data from a static e-commerce site, turning messy HTML into clean, structured information.
We'll be targeting a website called Books to Scrape, a sandbox built specifically for practicing web scraping. This means you don't have to worry about getting blocked by complex anti-bot measures while you're learning.

Fetching the Web Page
First, we need to get the page's HTML content. This is where the requests library comes in. We'll send an HTTP GET request to our target URL and check if we got a successful response.
Here is a complete, copy-pasteable example:
import requests
# The URL of the website we want to scrape
url = 'https://books.toscrape.com/'
# Best practice: define headers to mimic a real browser
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
# Send a GET request to the URL with a timeout
response = requests.get(url, headers=headers, timeout=10)
# Raise an exception for bad status codes (4xx or 5xx)
response.raise_for_status()
print("Successfully fetched the page!")
# Store the HTML content
html_content = response.text
except requests.exceptions.RequestException as e:
print(f"Failed to fetch the page. Error: {e}")
html_content = NoneA status code of 200 means "OK." If you get something else, like a 404 (Not Found), response.raise_for_status() will raise an HTTPError, which our try...except block will catch.
Parsing HTML with BeautifulSoup
Now that we have the raw HTML in html_content, we need to make sense of its structure. This is where BeautifulSoup shines. It transforms the messy string into a navigable Python object.
from bs4 import BeautifulSoup
# ... (previous requests code)
if html_content:
# Parse the HTML content of the page
soup = BeautifulSoup(html_content, 'html.parser')
# Let's print the title of the page to confirm it's working
print(f"Page Title: {soup.title.string}")When you run this, you should see "All products | Books to Scrape - A sandbox for web scrapers" printed, confirming BeautifulSoup has correctly parsed the document.
Finding and Extracting Data
This is the core of web scraping. To grab specific data, like a book's title or price, we must identify the HTML elements that contain them using your browser's "Developer Tools" (right-click -> "Inspect").
You'll notice each book is within an <article class="product_pod">. Inside, the title is in an <h3> tag and the price is in a <p class="price_color">. We can use BeautifulSoup's find_all() method to pinpoint these elements using CSS selectors.
# ... (previous code)
if 'soup' in locals():
# Find all the book containers on the page
book_containers = soup.find_all('article', class_='product_pod')
# Create a list to store our scraped data
books_data = []
# Loop through each book container to extract details
for book in book_containers:
# Extract the title from the h3 tag's anchor text, using .get() for safety
title_element = book.h3.a
title = title_element['title'] if title_element else 'No Title Found'
# Extract the price from the p tag with class 'price_color'
price_element = book.find('p', class_='price_color')
price = price_element.text if price_element else 'No Price Found'
# Add the extracted data as a dictionary to our list
books_data.append({'title': title, 'price': price})
# Print the first few results to check our work
import json
print(json.dumps(books_data[:3], indent=2))This script loops over each product "pod," extracts the title and price, and stores them in a structured list of dictionaries—data that's ready for use.
Step 2: Handling Complex Sites with the Olostep API
The scraper we just built works great on simple sites. But point it at a modern web app, and it will fail. Today's websites are loaded with JavaScript, shielded by anti-bot systems like Cloudflare, and use dynamic class names.
Trying to solve these issues yourself is a massive headache. It means wrangling headless browsers, managing rotating proxies, and deciphering CAPTCHAs. A smarter way is to offload this complexity to a specialized web scraping API.
Integrating the Olostep API for Robust Scraping
This is what the Olostep API was built for. Instead of hitting your target website directly, you send your request to Olostep. The API handles headless browsers, CAPTCHA solving, and proxy rotation, then sends back the clean, fully-rendered HTML.
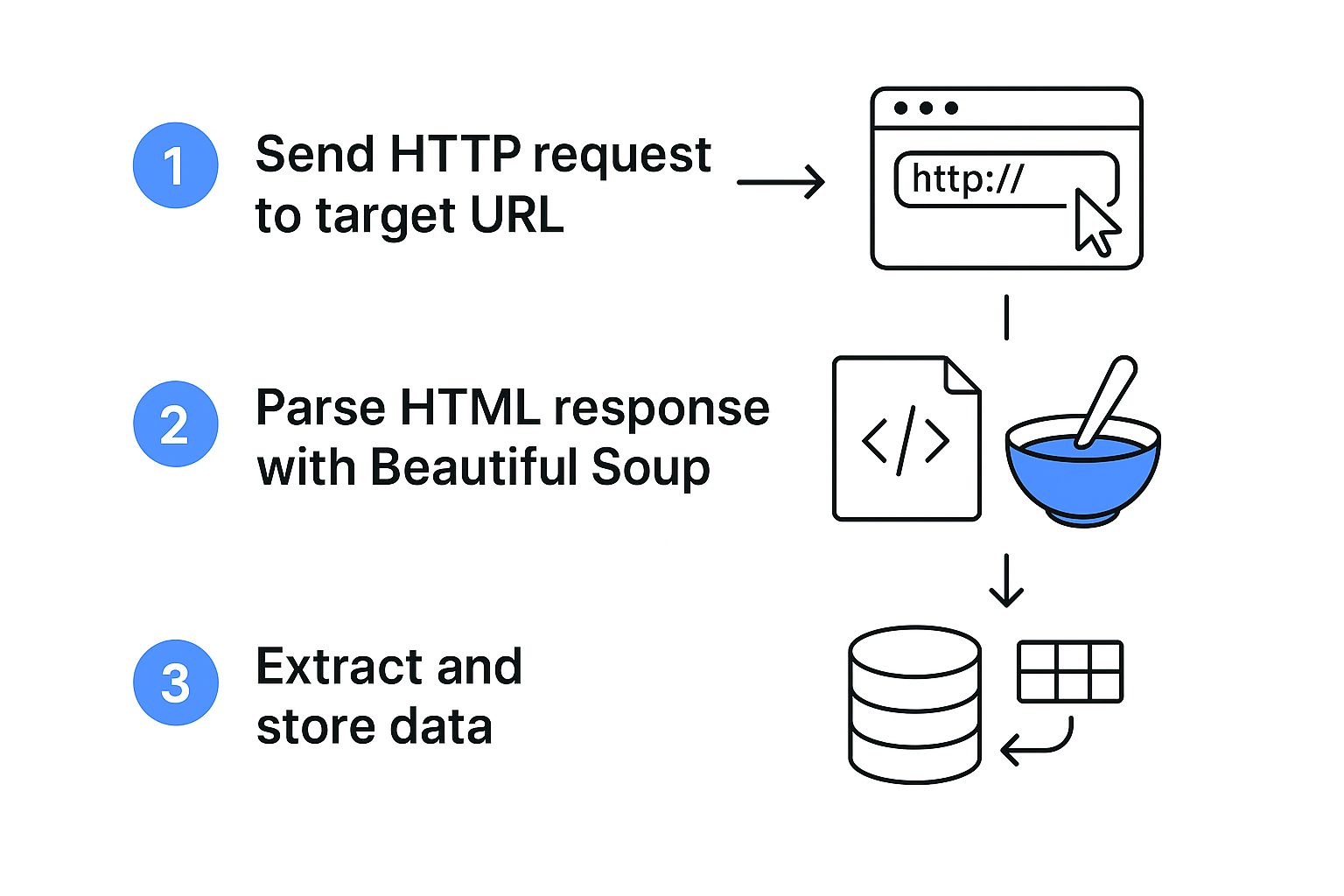
The demand for this API-driven approach is exploding. A staggering 87% of all scraping runs are now API-based, a trend detailed in Apify's full state of web scraping report.
Making a Scalable API Request with Python
Here is a practical, copy-pasteable Python example using requests to make a POST request to the Olostep API endpoint: https://api.olostep.com/v1/scrapes. You’ll need an API key from your Olostep account.
import requests
import json
import os
from bs4 import BeautifulSoup
import time
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# --- Configuration ---
OLOSTEP_API_KEY = os.environ.get("OLOSTEP_API_KEY", "YOUR_API_KEY")
OLOSTEP_API_URL = "https://api.olostep.com/v1/scrapes"
TARGET_URL = "https://quotes.toscrape.com/js/" # This site requires JavaScript
# --- Construct the Request Payload ---
payload = {
"url": TARGET_URL,
"javascript_rendering": True,
"wait_for": ".quote" # Optional: wait for a specific CSS selector
}
# --- Construct Request Headers ---
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {OLOSTEP_API_KEY}"
}
# --- Implement Retry Logic for API resilience ---
retry_strategy = Retry(
total=3,
status_forcelist=[429, 500, 502, 503, 504],
backoff_factor=1
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session = requests.Session()
session.mount("https://", adapter)
# --- Send the Request and Handle the Response ---
try:
print(f"Sending request to Olostep API for URL: {TARGET_URL}")
response = session.post(
OLOSTEP_API_URL,
headers=headers,
json=payload,
timeout=60 # A longer timeout for rendering
)
response.raise_for_status()
# --- Full API Response Payload ---
api_response_data = response.json()
print("--- Full API Response ---")
print(json.dumps(api_response_data, indent=2))
html_content = api_response_data.get("content")
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
quotes = soup.find_all('div', class_='quote')
for quote in quotes:
text = quote.find('span', class_='text').text
author = quote.find('small', class_='author').text
print(f"- '{text}' by {author}")
else:
print("API response did not contain HTML content.")
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
# You might want to inspect the response body for more details even on error
if 'response' in locals() and response.text:
print(f"Error Body: {response.text}")This script demonstrates the entire professional workflow. We construct a JSON payload telling the API to render JavaScript, set authentication headers, and use a requests.Session with a retry strategy for resilience. Once we get the successful JSON response, we extract the HTML from the content key and parse it with BeautifulSoup as before. This modular approach cleanly separates the hard part (fetching) from the easy part (parsing). You can find more targeted solutions in Olostep's custom web scrapers.
How to Evade Blocks and Scrape Ethically
A scraper that works once is a prototype. A scraper that works reliably is a tool. To build a robust tool, you must anticipate and handle anti-bot measures while respecting the websites you scrape.
Anti-Bot Evasion Techniques
- Rate Limits and Delays: Don't hammer a server with rapid-fire requests. Introduce random delays between requests (
time.sleep(random.uniform(1, 4))) to mimic human browsing behavior. - User-Agent Headers: Always set a realistic
User-Agentheader. Cycle through a list of common browser user agents to avoid being flagged as a primitive bot. - Proxy Rotation: The most effective technique. Use a large pool of rotating proxies (datacenter or residential) so requests appear to come from many different users. Services like Olostep manage this for you automatically.
- Respect
robots.txt: This file, found at the root of a domain (e.g.,domain.com/robots.txt), outlines rules for bots. While not legally binding, respecting it is a core tenet of ethical scraping and helps you avoid blocks.
Our guide on how to scrape without getting blocked covers these strategies in greater detail.
Ethical and Legal Considerations
Web scraping exists in a legal gray area that is constantly evolving. The landmark hiQ Labs v. LinkedIn case affirmed that scraping publicly accessible data is generally not a violation of the Computer Fraud and Abuse Act (CFAA), but this does not give you a free pass.
- Public vs. Private Data: Never scrape data that is behind a login or authentication wall.
- Personal Data: Be extremely careful when dealing with personally identifiable information (PII). Adhere to regulations like GDPR and CCPA.
- Terms of Service (ToS): A website's ToS may explicitly forbid scraping. While the enforceability of this is debated, violating it can lead to your IP being banned or legal action.
- Server Load: A poorly designed scraper can act like a Denial-of-Service (DoS) attack. Scrape during off-peak hours and keep your request rate low to avoid impacting the site's performance.
Always consult with a legal professional if you are unsure about the specifics of your project. For a deeper dive, check out this overview of the legality of web scraping.
Troubleshooting Common Web Scraping Failures
Even with the best tools, things will go wrong. Here’s how to troubleshoot the most common issues.
- CAPTCHAs: If you encounter a CAPTCHA, your IP has been flagged. Simple CAPTCHAs can sometimes be solved with specialized services, but complex ones like reCAPTCHA are nearly impossible for a script to beat. This is a primary reason to use a scraping API, as they handle CAPTCHA-solving at scale.
- 403 Forbidden Error: This means the server understands your request but refuses to authorize it. The most common cause is a missing or blacklisted
User-Agentheader. Try using a standard browser User-Agent. If that fails, your IP is likely blocked. - 429 Too Many Requests Error: You've hit a rate limit. The solution is to slow down. Implement exponential backoff in your retry logic, waiting longer between each subsequent request.
- 5xx Server Errors: These indicate a problem on the server's end (e.g.,
503 Service Unavailable). These are usually temporary. A robust retry strategy is the best way to handle them. - Timeouts: The server is taking too long to respond. This can be due to network issues or an overloaded server. Always include a
timeoutparameter in yourrequestscalls (e.g.,timeout=15) to prevent your script from hanging indefinitely.
Comparing Web Scraping API Alternatives
While Olostep offers a powerful toolkit, it's wise to understand the landscape. The market is packed with solid options, and choosing the right one depends on your specific needs for features, pricing, and developer experience. The web scraping market is growing rapidly, with a recent 2025 web scraping market report highlighting its increasing integration with AI and business intelligence.
Here's a fair comparison of the key players:
| API Provider | Key Features | Pricing Model | Best For |
|---|---|---|---|
| Olostep | High concurrency, structured data parsers, advanced rendering options (wait for element, etc.). | Credit-based; pay-as-you-go and subscriptions. | Developers and businesses needing reliable, scalable scraping with fine-grained control. |
| Bright Data | Massive proxy network (72M+ IPs), SERP API, extensive data collection tools. | Pay-per-IP/GB and subscription plans; can be complex. | Enterprises requiring large-scale, geographically diverse data collection. |
| ScrapingBee | Simple API, JavaScript rendering, screenshot capabilities, and data extraction rules. | Credit-based subscriptions based on API calls and features. | Developers and small teams looking for a user-friendly and straightforward solution. |
| ScraperAPI | Custom headers, IP geolocation, CAPTCHA handling, and a large proxy pool. | Subscription-based on the number of successful API calls. | Projects needing reliable proxy rotation without much configuration. |
| Scrapfly | Python/TypeScript SDKs, browser scraping, anti-bot bypass features. | Subscription-based on bandwidth and features used. | Developers who prefer an SDK and need to bypass advanced bot detection. |
Ultimately, the best choice comes down to balancing technical requirements with your budget. Our guide on the top web scraping tools dives even deeper into these nuances.
Final Checklist and Next Steps
You've covered a tremendous amount of ground, from writing your first simple scraper to deploying a robust, API-driven solution. Here is a final checklist to ensure your projects are successful.
Web Scraping Project Checklist
- Define Clear Objectives: What specific data points do you need?
- Analyze the Target Site: Is it static or dynamic (JavaScript-heavy)? Check
robots.txt. - Set Up a Clean Environment: Use a virtual environment and a
requirements.txtfile. - Start Simple: Use
Requests+BeautifulSoupfor your initial prototype. - Implement Resilience: Add error handling (
try...except), timeouts, and retry logic. - Behave Ethically: Set a realistic
User-Agent, respect rate limits, and scrape responsibly. - Scale with an API: When facing blocks or JavaScript, integrate a service like Olostep to handle the complexity.
- Structure and Store Data: Parse extracted data into a clean format (JSON, CSV) and save it.
Next Steps
- Practice on Different Sites: Apply these techniques to websites with varying structures and challenges.
- Explore Data Storage: Learn to save your scraped data into databases (like SQLite or PostgreSQL) or cloud storage.
- Automate Your Scripts: Use tools like Cron (on Linux/macOS) or Task Scheduler (on Windows) to run your scrapers on a schedule.
- Build a Full Application: Integrate your scraper into a larger project, like a price monitoring dashboard or a data analysis pipeline.
Ready to bypass blocks and handle any website with ease? Olostep provides a powerful, scalable web scraping API that manages proxies, JavaScript rendering, and anti-bot measures for you. Get started for free and focus on what matters—your data. Sign up at Olostep.


